

所有用英伟达Blackwell B200的人,都在花冤枉钱??
普林斯顿大学等联合团队指出,这款GPU居然因为软硬件适配问题白白浪费了60%的计算资源。

算力浪费了,咋办呢——FlashAttention-4给出了答案。
这款专为Blackwell架构GPU量身打造的注意力算法,一举将利用率从行业普遍的20%-30%推至71%。
FlashAttention-4由Tri Dao领衔、携手Meta、Together AI等团队共同研发。
嗯,英伟达自己也参与其中了……

Blackwell B200有力使不出
英伟达Blackwell B200作为新一代数据中心GPU,其tensor core张量核心算力达到2.25 PFLOPS,是上一代Hopper H100的2倍。
理论上能让注意力计算的速度实现跨越式提升。
但理想很丰满……
这款GPU发生了严重的偏科。
核心算力猛增的同时,关键的配套计算单元却原地踏步。
其中,负责指数运算的MUFU单元吞吐量与Hopper架构完全一致,没有任何提升;
共享内存的带宽也保持原样,并未跟随张量核心同步升级。
这一硬件设计的不对称性,直接导致了性能瓶颈的反转。
在大模型核心的注意力计算负载中,原本的性能瓶颈矩阵乘法,如今耗时远低于辅助环节,共享内存的读写操作和指数运算的耗时,反而比矩阵乘法多出25%-60%。
算力翻倍的Tensor Core长期处于等待状态,大量计算资源就这么被闲置了。
于是,大量开发者花费重金部署的B200 GPU,因核心算力与配套单元的脱节,超六成资源被白白浪费。
算力翻倍?
No!明明是有力使不出……
FlashAttention-4三招破解瓶颈
针对Blackwell GPU的偏科问题,FlashAttention-4量身打造了三大优化策略。
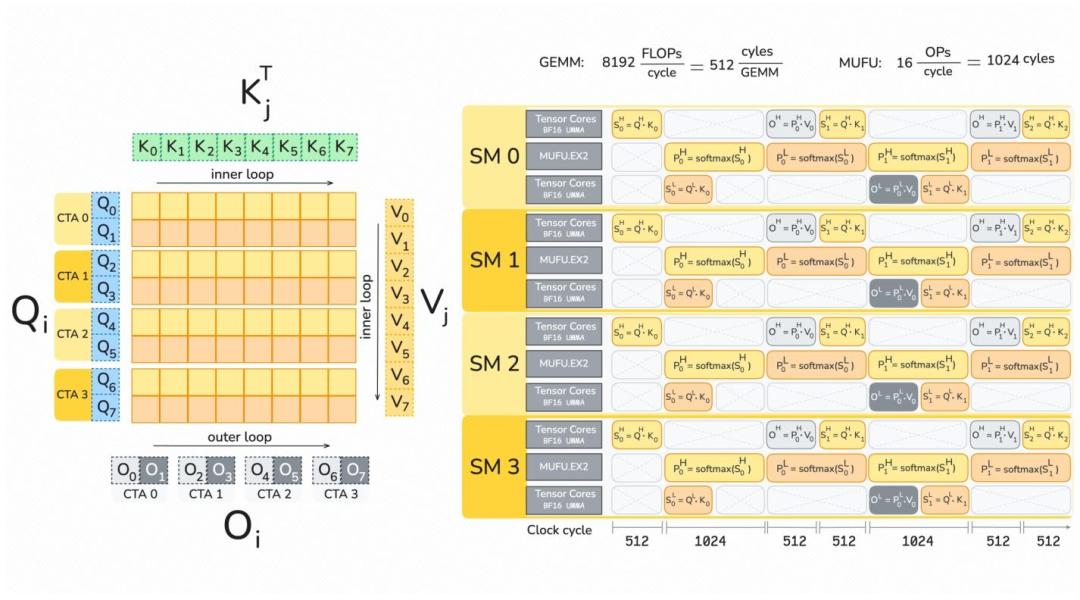
第一招,多管齐下化解指数运算与内存读写难题。
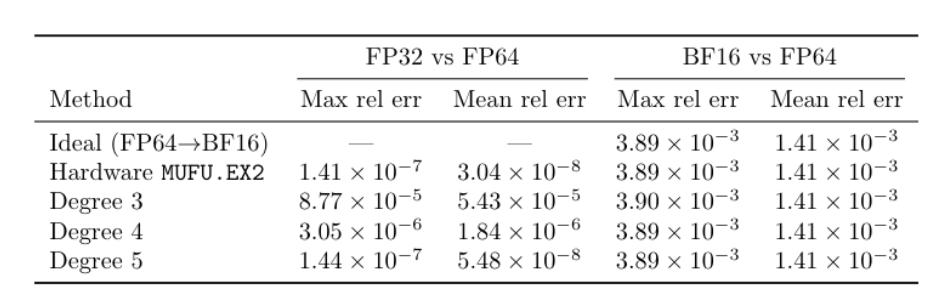
团队一方面通过软件模拟指数函数,借助多项式近似的方法,让高速的FMA计算单元参与到原本由MUFU单元负责的指数运算中,大幅提升指数计算的吞吐量;
同时通过混合硬件计算与软件模拟的方式,在提速的同时保证计算精度。
另一方面推出条件性softmax rescaling策略,仅在必要时执行softmax的缩放操作,直接跳过大量无用的计算步骤,减少非矩阵乘法的运算量。
此外,团队充分利用Blackwell架构的2-CTA MMA模式,让两个计算单元搭档完成矩阵运算,各自仅加载一半的运算数据。
这就将共享内存的读写量直接砍半,同时还减少了后续的原子操作,从根源上缓解共享内存的带宽压力。
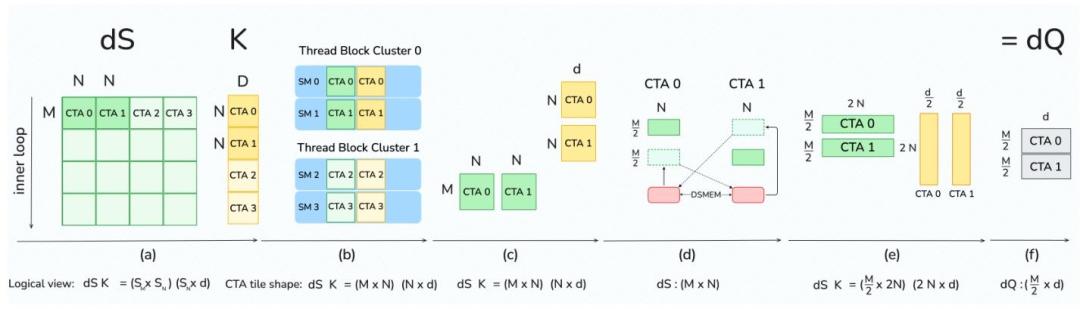
第二招,重构计算流水线,实现算力的并行最大化。
FlashAttention-4深度适配Blackwell架构的全异步MMA操作和新增的张量内存TMEM,重新设计了注意力计算的前向和反向流水线。
让softmax计算与矩阵乘法这两个核心环节实现完全的计算重叠。
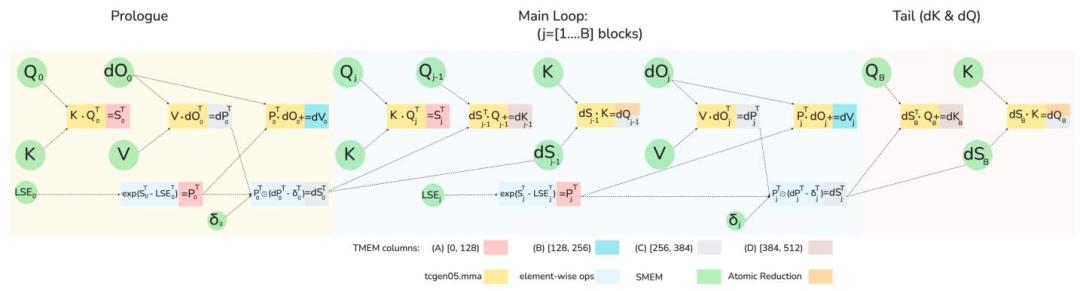
当硬件的张量核心在处理一个矩阵块时,另一部分硬件资源可同时对另一个数据块执行softmax计算,避免硬件算力的空闲。
第三招,兼顾硬件迭代,为下一代GPU预留优化空间。
研发团队同时考虑到Blackwell架构的硬件升级趋势,目前B300/GB300 GPU的指数运算单元吞吐量已翻倍至32 ops/clock/SM。
针对这一变化,团队明确表示,FlashAttention-4当前的软件模拟指数运算方案,在下一代硬件上会根据实际性能表现重新权衡,确保算法能持续适配硬件的迭代升级。
告别 C++,编译速度狂飙30倍
除了算法层的深度优化,FlashAttention-4在开发层面也带来了变化。
与此前基于C++模板开发的FlashAttention-3不同,FlashAttention-4的全部代码基于Python的领域专用版本CuTe-DSL框架编写,实现了零C++代码开发。
这一设计带来的是编译的效率跃升。
前向传播内核的编译时间从FlashAttention-3的55秒缩短至2.5秒,提速22倍;
反向传播的编译时间从45秒降至1.4秒,提速32倍,整体编译速度最高狂飙30倍。

在B200 GPU上的实测数据显示,其前向传播算力最高达到1613 TFLOPS/s,一举实现71%的理论峰值利用率。
对比主流的计算框架,FlashAttention-4的优势也比较明显。
比英伟达官方的cuDNN 9.13快1.1-1.3倍,比常用的Triton框架快2.1-2.7 倍。
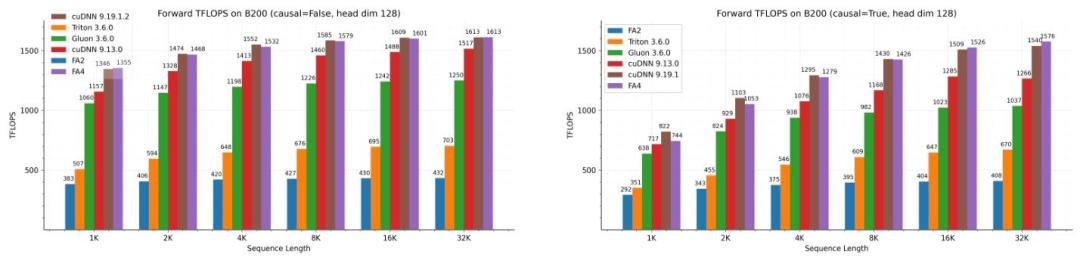
且在长序列、因果掩码等大模型训练推理的核心场景中,性能优势更为突出。
One More Thing
论文还指出,cuDNN从9.13版本开始就已经开始反向吸收了FA4的核心技术。

看来,英伟达自己也忍不住抄作业了(doge)。
论文地址:https://arxiv.org/abs/2603.05451
参考链接:https://x.com/alex_prompter/status/2033885345935462853?s=20
