

在今年的 GTC 上,黄仁勋重新定义了英伟达:一家垂直整合、横向开放的公司。
这与外界对这家芯片巨头的固有印象截然不同。过去,英伟达专注于高性能 GPU 的研发,并利用 CUDA 生态绑定开发者,以此构筑起牢固的护城河。
但 AI 浪潮推着英伟达自我颠覆。一方面,在硬件上走向垂直整合——其新一代 Vera Rubin 计算平台从一颗芯片进化为一整套芯片系统。软件则走向合作开放——与 OpenClaw 合作推出 NemoClaw,允许在英伟达以外的硬件平台上运行。
黄仁勋算了一笔账:到 2027 年,以 Blackwell 和下一代 Vera Rubin 为主的 AI 加速芯片的累积营收将达到一万亿美元。为了吞下这一万亿美元,英伟达不仅需要改良 “铲子”,还要找到新的商业模式,把它送到买铲人手上。
从一颗芯片,到一整套芯片系统
英伟达的下一代计算平台 Vera Rubin 不再只是单颗芯片,而是由 7 款定制芯片和 5 种不同机架组成的芯片系统。通过最新的 NVLink 6 网络,它将 72 颗 Rubin GPU 和 36 颗 Vera CPU 在微秒级延迟下连接成一个超级芯片。
其中,Vera CPU 集成了 256 颗液冷处理器,计算效率是传统 CPU 的两倍。黄仁勋强调,该产品专为代理型 AI(Agentic AI)优化,且将首次作为独立的 CPU 产品向市场出售。
过去 AI 训练和执行任务,英伟达的 GPU 虽然承担了大部分繁重工作和计算任务,但必须采购 Intel 或 AMD 的 X86 架构 CPU 来做系统的核心大脑。现在英伟达推出了自己的 Vera CPU。黄仁勋称,在与 Rubin GPU 整合后,Vera Rubin 的单卡推理能力较上一代 Blackwell 芯片提升最高 5 倍,大模型生成 Token 成本降低 90%。
阿里巴巴、字节跳动和 Cloudflare 等云服务提供商已经宣布将部署 Vera CPU 机架,英伟达预计将在今年下半年向首批客户交付。
Vera Rubin 的 7 颗芯片中,还包含一颗 Groq 3 LPU(Language Processing Unit,语言处理单元),用于 AI 推理任务的加速。
去年底,英伟达斥资 200 亿美元获取初创公司 Groq 的低延迟推理等核心技术。在本次 GTC 上,英伟达首次发布了其整合成果——将 Groq 3 LPU 与 Vera Rubin 平台协同部署。
不同于目前主流的 GPU 方案,需要外置一个高宽带内存(HBM)来储存数据,LPU 把数据留在芯片内处理,所以 Groq 3 在回答问题、生成内容时的延迟更低,更稳定,这正好可以弥补英伟达计算架构在推理速度方面的不足。
在被收购前,Groq 由于走了不同的技术路线,并且发布了证明实力的低延迟 LPU,曾被视为英伟达潜在的挑战者。而现在,英伟达在全新的机架配置中,专门留出了一个 “Groq 3 LPX 推理托盘”,直接把行业里延迟最低的技术变成自家的拔插式模块,弥补了自身短板,还把潜在的竞争风险消弭于无形。
重返消费级 SoC
除了 Vera Rubin 和 Groq 3,今年 GTC 上的另一个重要硬件产品是英伟达与联发科(MediaTek)共同研发的 N1X 芯片。这是一款基于 Arm 架构的 SoC(终端高集成度芯片),主要面向高端 AI PC 和笔记本电脑市场。
N1X 效仿苹果 M 系列芯片,把 CPU、GPU 和 AI 加速单元全部接在同一块物理内存池上,从而优化了延迟和能耗问题。
这不是英伟达第一次进军消费级 SoC。它曾在 2011 年面向移动端处理器推出 “丹佛计划”,并在 2021 年推出面向数据中心的 Grace CPU。前者铩羽而归,后者的战果局限在 AI 专用基础设施上。
而现在,英伟达正在冲击 AI 运行的全面底层硬件。在云端,英伟达有集成了 CPU 的 Vera Rubin,打破了传统 x86 架构在 AI 服务器中的优势地位,并且面对快速推理的需求,能通过 Groq 3 LPU 来填缝。而在个人 PC 处理器市场,英伟达也试图通过 N1X 分一杯羹。
这种策略也提升了竞争者的门槛,想替代英伟达,不能只靠一块性能更好的 GPU,而要同时造出更好的 CPU、交换机、网络协议和低延迟模块。
在 AI 基础设施的硬件上,英伟达显然想赚到每一块铜板。
硬件不是壁垒,软件才是
与极度排外的硬件全家桶不同的是,英伟达在软件上是另一套策略。
在本次 GTC 上,英伟达宣布与近期爆火的开源项目 OpenClaw 合作,推出 NemoClaw。NemoClaw 是面向企业市场的开源AI智能体平台,可以帮助企业一键部署、运行和管理 AI Agent。
反常的是,黄仁勋宣布 NemoClaw 不限制硬件,这意味着不仅能跑在英伟达的显卡上,也能跑在竞争对手 Intel 和 AMD 的芯片上。
十多年来,英伟达最深的护城河是 CUDA 生态,而 CUDA 与英伟达的显卡绑定在一起,形成软硬件一体的护城河。
但是现在,这位 AI 硬件霸主竟然主动解绑。
黄仁勋这么做,是基于对行业未来的判断。当下,微软的 Maia、谷歌的 TPU 等云厂商自己研发的定制化 AI 芯片,已经获得了市场近 40% 的份额(Intel Market Research 数据)。
如果单纯只拼 GPU 算力参数,在物理极限的制约下,差距缩小是必然。如果芯片的护城河注定要缩水,英伟达该拿什么留住客户?
答案就是软件。
黄仁勋在演讲中说,虽然现在生成式 AI 非常火热,但是对于企业级应用来说,最核心的基础还是结构化数据(structured data,包括 SQL、Spark、Pandas 等),黄仁勋称之为 “巨大的电子表格(giant spreadsheets)”,而收集、处理好这些数据,能给企业带来最大的价值。
基于这个判断,英伟达正在做的,就是让全球企业在处理这些结构化数据、构建 Agent 工作流时,都习惯调用 NemoClaw 提供的 API 和微服务,为了完善软件生态闭环,英伟达刚刚在本月发布了自己的大语言模型 Nemotron 3。
黄仁勋的意思再明白不过——用谁的软件,比软件在谁家芯片上跑更重要。而只有降低企业的使用门槛,让更多企业把 AI 变成基建,让整个社会对 AI 需求的盘子变大,市场对高端算力的需求才会更多。
从这个角度讲,开源的 NemoClaw 不仅不是赔钱业务,而是最好的营销。就像谷歌的安卓操作系统也是开源的,不直接产生利润,但可以靠应用商店和云服务盈利,而在英伟达这里,应用商店和云服务换成了 GPU 和 token。英伟达甚至大方的表示,你用谁的 GPU 和模型都可以。
在软件和硬件之上,黄仁勋的演讲中还重点提到了 “AI 五层蛋糕”(The 5 Layer AI Cake)理论,这是他在本次大会上的核心概念,也可以理解为英伟达战略思考的起点。
这个理论提出,AI 是一个巨大的蛋糕,蛋糕从下到上依次是:能源、芯片、数据中心、模型、应用。最顶层,也就是应用层的每一次进步,都会向下带来大量需求,而且各层之间相互依存。
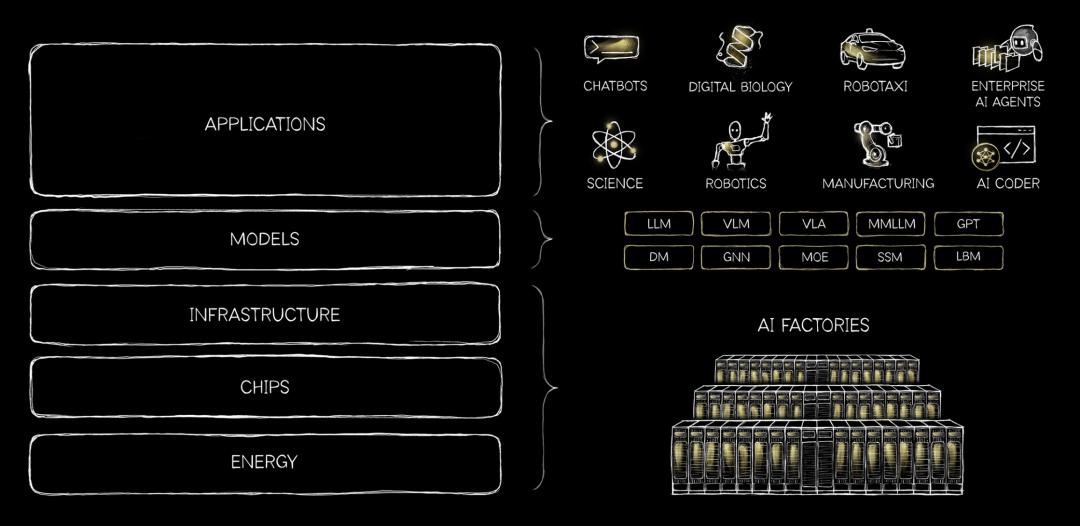
AI 的五层蛋糕示意图
从去年开始的关于 AI 泡沫的讨论里,看空者总是担心,等那几个大厂把模型训练完了,英伟达的显卡卖给谁?
面对质疑,黄仁勋重新设置了议程:你觉得过去的故事不性感,我给你换个全新版本。
通过这次 GTC,就能看出黄仁勋给出的回应逻辑,就是在 AI 的每一层都进行押注,让这个 AI 流水线动起来。除了英伟达重点布局的中间三层,在最底层能源层,英伟达投资了核电,在最顶层应用层,英伟达投资了医疗 AI 和自动驾驶等方向。
换句话说,英伟达正在做的事,投资也好,软硬件也好,从宏观来说都是在把 AI 产业的盘子做大,并且避免这五层中哪一层卡住。而一旦这个流水线流动起来了,全世界对于英伟达的算力需求就不会少。这也是为什么黄仁勋在 GTC 开场时就表示,“本次大会将涵盖人工智能这座 ‘五层蛋糕’ 的每一层。”
如果说之前的英伟达还只是淘金热里的一个热门卖铲人,那么今天的英伟达,已经买下了水源、修好了铁路,并且投资了那些最有潜力的淘金人,甚至开始送铲子了。正如在演讲中,黄仁勋重新定义的英伟达:“我们是一家垂直整合的计算公司,别无他法。”
