

1、上海交大集成电路学院周林杰、陆梁军团队在片上集成光子计算领域取得新进展
2、中国科大揭示合成氨反应中氮化物动态包覆高效催化新机制
3、厦门大学:光子晶体中紧束缚耦合的可编程调控
4、上海交大计算机学院智能软件与系统研究所OASIS课题组再获国际存储顶会USENIX FAST最佳论文奖
1、上海交大集成电路学院周林杰、陆梁军团队在片上集成光子计算领域取得新进展
近日,上海交通大学集成电路学院(信息与电子工程学院)周林杰教授、陆梁军教授团队在片上集成光子计算领域取得新进展。团队提出一种基于时-波-空交织的集成光子3D张量处理引擎(3D-TPE),通过微环光开关阵列和可调延时线阵列芯片的协同调控,在光域内实现了数据缓存、通道时钟同步与张量计算,具备灵活时钟频率调控能力,在20 GHz主频下执行激光雷达3D点云图推理任务,达97.06%识别准确度。相关成果以“Integrated photonic 3D tensor processing engine” 为题发表于国际期刊《Light: Science & Applications》。

研究背景
随着人工智能技术的飞速发展,深度学习任务对现有计算体系的算力吞吐量、处理延迟和能效比提出了极高要求。然而,现有电子计算架构受限于“冯·诺依曼瓶颈”与“存储墙”效应,其功耗与算力难以进一步提升。光子计算凭借其高带宽、低延迟、高并发性以及丰富的物理调控自由度等优势,被广泛视为解决未来超大规模算力需求,实现高吞吐量和高能效计算新范式的强有力的候选者之一。然而,当前大多光子硬件加速器多聚焦于2D矩阵-向量乘法计算的优化,面对神经网络中作为基本数据结构的高维张量的计算处理时,现有的2D架构面临显著挑战。首先,高阶张量需根据光子硬件规模在电域进行频繁的结构重塑与中间计算结果的缓存,引入了额外的计算开销、存储开销与时间延迟。其次,多通道数据的时序同步高度依赖外部电子时钟,缺乏在光域内直接进行数据缓存和时序对齐的能力,随着光子阵列规模的扩大,电控同步系统的复杂度急遽增加,难以发挥出光子计算在超高主频下的算力潜力与实时处理能力。
研究内容
研究团队提出了一种基于时间-波长-空间交织的集成光子3D张量处理引擎(3D-TPE),如图1所示。该光子引擎通过深度协同光计算单元(OCU)与光缓存单元(OMU),在光域内实现了数据缓存、通道时钟同步与张量计算,并具备灵活的时钟频率适配能力。光计算单元(OCU)由双耦合微环交叉阵列芯片构成,光缓存单元(OMU)采用可调时间延迟线阵列实现。输入数据经调制器顺序加载到多波长光载波上并馈入多路光计算通道,实现输入信号在波长域和空间域的多样本复制;通过精准调控不同光计算路径中信号副本的延迟量,实现多通道信号的光域数据缓存与通道间时序对齐;通过光计算单元完成并发的加权乘法计算,并经光电探测器实现输出功率的线性累加。通过OCU与OMU芯片的协同调配,片上光子矩阵计算规模也从传统的2D矩阵-向量乘法计算拓展为3D矩阵-矩阵乘法计算。该3D-TPE通过将数据缓存、通道时钟同步任务从电域移至光域,进一步释放了光子计算系统中外部电子高速调控的需求,充分释放了光在高速、高并行度下的计算优势,其自适应的时钟频率调控能力也使其在其能够灵活应对时间密集型或时间稀疏型任务。
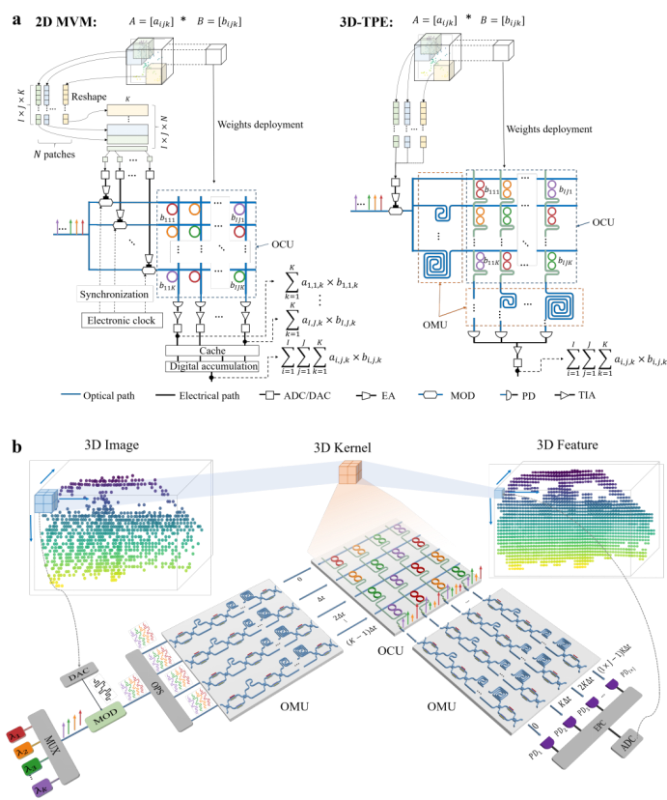
图1 集成光子3D张量处理引擎:(a) 传统2D MVM光子加速器与本文提出的3D-TPE对比;(b) 3D-TPE结构概念示意图光计算单元(OCU)基于双耦合微环交叉阵列芯片,与传统方案单微环权重元素相比,双耦合微环权重元素具有更平坦的光谱响应与更大的光学带宽,能减小高码率下的信号失真,并提升对激光波长漂移的鲁棒性。图2展示了团队所制备的光计算芯片,权重元素的3 dB带宽达50 GHz,通道间串扰小于-25 dB,通过简单的查表法,即可实现任意权重组合下稳定超过7 bit的权重部署精度。
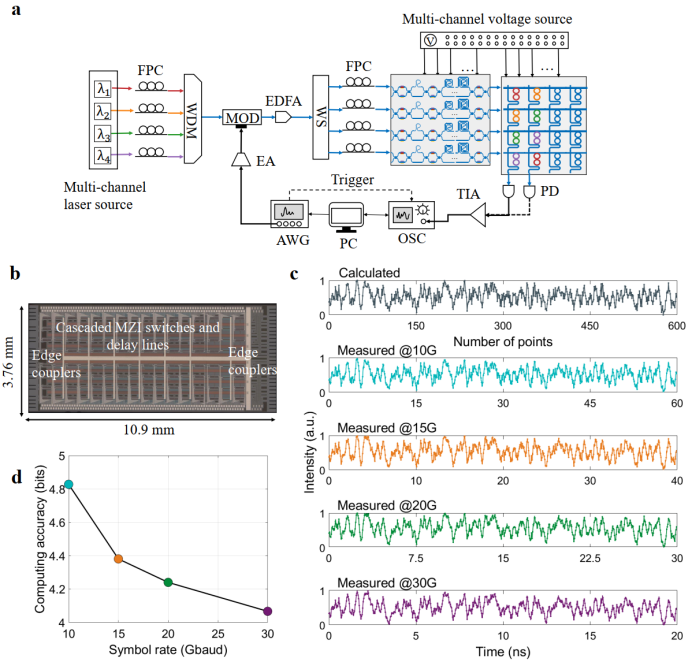
图2 基于3D双耦合微环光交叉阵列的光计算单元(OCU):(a)芯片光镜图;(b)权重单元;(c)光谱特性;(d) 权重调控;(e)权重电压映射曲线;(f-g)任意权重组合下的权重部署(f)实验与理论对比散点图以及(g)精度光缓存单元(OMU)由一个8通道可调时间延迟线阵列芯片构成,如图3所示。单个可调时间延迟线由7个级联MZI光开关及连接延迟波导组成,延迟分辨率为4.93 ps(对应约200 GHz的自适应时钟频率),最大延迟时间达310.59 ps,延迟误差被严格控制在0.6 ps以内。通过调配不同光学路径的时间延迟量,团队进行了10 Gbaud到30 Gbaud码率下的系统计算能力评估,系统测试表明,在固定权重组合下的4通道并发计算精度为4.1至4.8 bits之间。
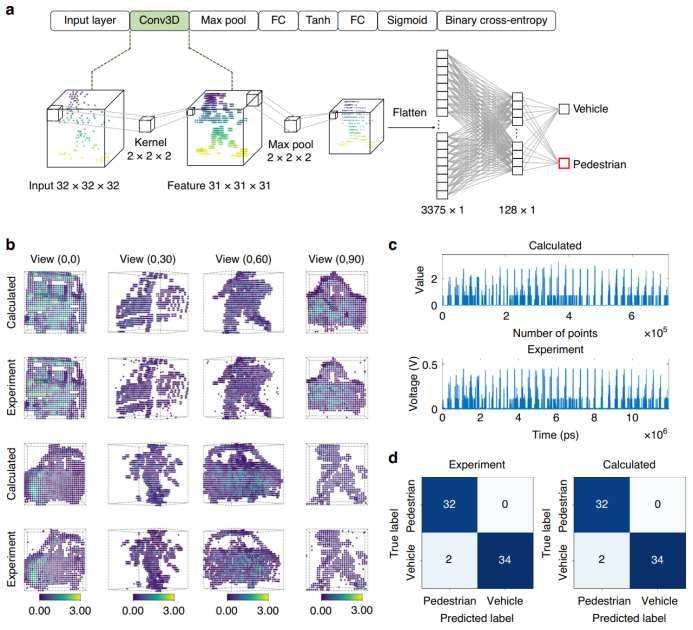
图3 用于时钟频率调控的光缓存单元(OMU): (a) 实验装置图;(b)光缓存单元芯片光镜图;(c-d)10G至30G码率下的理论计算与实验(c)波形对比与(d)等效计算精度在概念验证实验中,团队使用该3D-TPE光子计算引擎执行了3D CNN中卷积层的卷积计算,如图4所示。在20 GHz的系统时钟频率下,执行了激光雷达3D点云图像识别推理任务,达到97.06% 的识别准确率,其结果与数字计算结果相当。
图 4 激光雷达3D点云图像推理任务:(a) CNN架构;(b-d) 数字计算与光计算实验结果对比(b)不同角度下的点云特征图对比,(c) 特征图波形对比以及(d)识别混淆矩阵对比论文作者信息上海交通大学集成电路学院(信息与电子工程学院)博士生吴月、博士毕业生倪子恒为共同第一作者。上海交通大学集成电路学院(信息与电子工程学院)陆梁军教授、周林杰教授为通讯作者。该工作得到了学院陈建平教授的悉心指导。学院博士毕业生李鑫、硕士毕业生王媛荀也为本工作做出了重要贡献。此外,该工作得到了上海交通大学光子传输与通信全国重点实验室、上海交通大学–平湖智能光电研究院、国家重点研发计划、国家自然科学基金的支持。

陆梁军,教授,主要研究方向为硅基光电子集成芯片及系统应用。主持重点研发计划项目、基金委面上等项目10余项。在Nat. Commun., Light Sci &Appl., PhotoniX, Optica等国内外一流期刊发表论文90余篇,持有中国发明专利30余项,美国专利5项。入选国家高层次青年人才、上海市启明星计划,曾获中国电子学会科技进步二等奖等。

周林杰,教授,国家级高层次人才,主要从事光电子器件与集成方面研究工作。主持各类国家级科研项目20余项,在Nature Photonics、Nature Communications、Physics Review Letters、Light Science & Applications、Advanced Photonics等期刊发表论文200余篇,Google Scholar统计引用超过8000次。入选爱思唯尔中国高被引学者榜单、英国皇家学会牛顿高级学者。曾获中国光学“十大进展”、中国产学研合作创新奖、华为优秀合作奖、中兴优秀项目奖等。论文链接:https://www.nature.com/articles/s41377-026-02183-y 作者: 集成电路学院(信息与电子工程学院) 供稿单位: 集成电路学院(信息与电子工程学院)
2、中国科大揭示合成氨反应中氮化物动态包覆高效催化新机制
来自中国科学技术大学的李微雪教授团队在温和条件氨合成催化理论机制研究领域取得重要进展,相关研究成果以“Strong Metal‒Metal Interaction-induced Encapsulation of Cobalt by Lanthanum Nitride for Efficient Ammonia Synthesis”为题,3月16日正式发表于《Journal of the American Chemical Society》。这项工作终结了氮化物基合成氨领域长期存在的核心机理争议,首次将团队原创的强金属-金属作用(SMMI)动态包覆理论从氧化物体系拓展至氮化物体系,建立了统一的催化理论框架,为温和条件高效合成氨催化剂的理性设计提供了新范式。
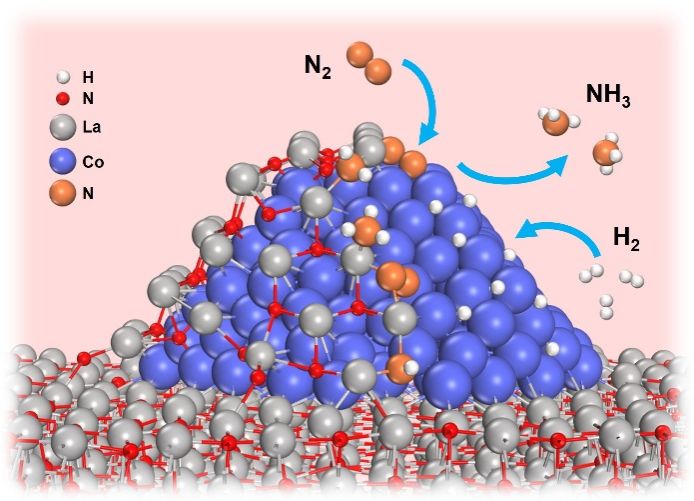
图1. LaN包覆Co形成界面活性位催化合成氨反应示意图
氨是全球化工产业的核心基石,既是保障全球粮食安全的氮肥核心原料,也是极具应用前景的零碳能源载体与高密度储氢介质。当前工业合成氨高度依赖已有百年历史的哈伯-博施法,该工艺需在400℃以上高温、100个大气压以上高压的严苛条件下运行,年能耗占全球总能耗的1%以上,伴随显著的碳排放压力。开发能在温和条件下高效运行的合成氨催化剂,是催化科学与能源化工领域的重大科学挑战,对全球可持续发展与国家能源安全具有深远意义。
近年来,氮化物负载金属催化剂因优异的低温合成氨活性成为领域研究热点。系列开创性工作发现,单独的氮化镧(LaN)载体与钴(Co)、镍(Ni)金属纳米颗粒均无显著催化活性,而二者复合后展现出远超传统催化剂的低温性能。此前学界先后提出“氮空位双位点”、“金属原子自旋介导”等模型解释其催化机制,但始终无法完整合理解释多样的实验现象,活性位点的原子级本质、金属-载体协同作用的物理起源长期存在争议,缺乏统一的热力学与动力学理论框架,严重制约了该类催化剂的定向设计与性能优化。合成氨作为检验多相催化基础理论的经典“圣杯反应”,该领域的核心机理争议,也成为制约催化基础理论发展的关键瓶颈。
针对这一核心科学难题,李微雪教授团队以LaN负载Co纳米颗粒为原型体系,整合从头算原子热力学、机器学习势驱动的分子动力学模拟、第一性原理计算与微动力学模拟等多尺度研究方法,系统构建了该类催化剂的统一催化机制框架,取得了一系列原创性科学发现。
团队首先通过理论计算,系统阐明了单一组分的固有催化缺陷:纯金属Co表面在反应条件下极易被氢原子全覆盖,引发严重的氢中毒效应,大幅削弱氮气吸附能力并显著升高氮气解离能垒(图2);而LaN载体虽易活化氢气,但晶格氮加氢与氮空位生成存在严苛的热力学瓶颈,无法完成持续的催化循环,本征催化活性可忽略不计。这一结果明确了该体系的高催化活性并非来自单一组分,而是源于金属-载体界面形成的特殊结构与协同作用。
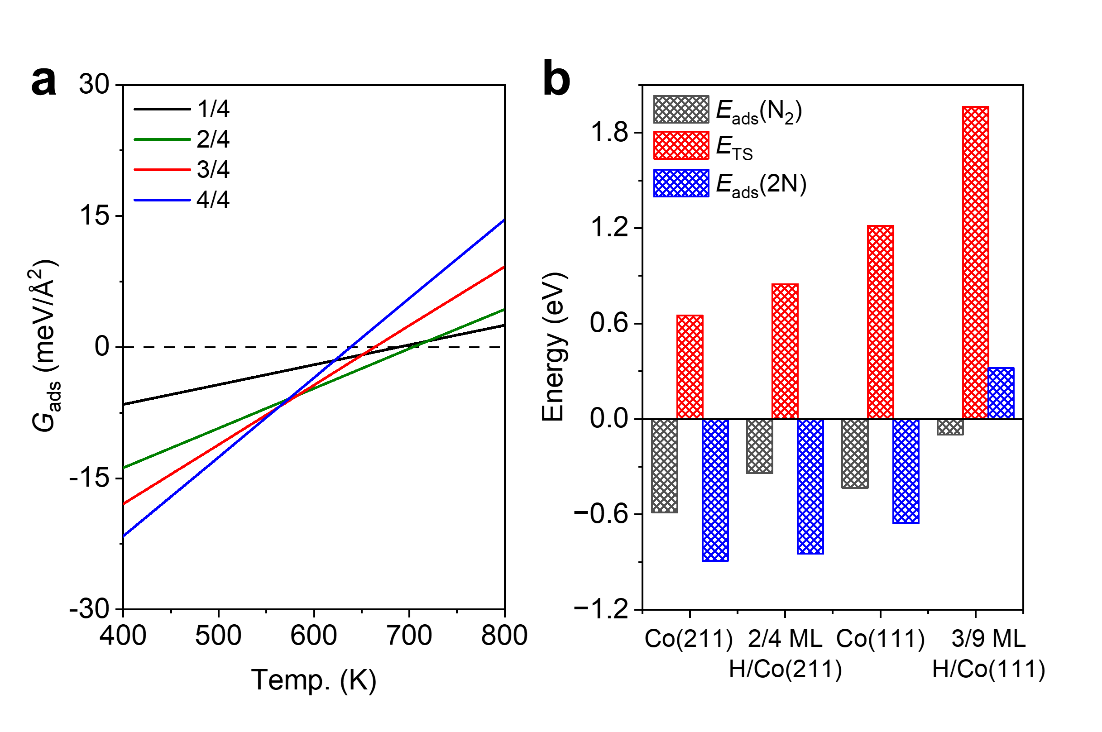
图2.(a)氢分子合成氨反应条件下在Co(211)表面上的吸附相图(1atm,H2:N2=3:1)。(b)氮分子在钴单晶表面上的解离吸附。
研究团队前期针对氧化物负载的金属催化剂,建立发展了金属-载体作用(MSI)调控的烧结稳定性理论 (Science 374 (2021)1360),结合可解释性人工智能发现了解析描述MSI的物理方程,提出了SMMI载体包覆金属催化剂判据(Science 386 (2024) 915)。在最新的研究中,研究团队首次将该理论从氧化物体系成功拓展至氮化物体系。理论计算明确,Co与La之间的相互作用强度超过La-La的相互作用强度,从热力学上证明了LaN对Co纳米颗粒的包覆效应会自发发生。团队进一步通过机器学习势驱动的分子动力学模拟,完整再现了这一动态结构演化过程:LaN表层的氮空位是包覆过程发生的动力学关键,在氮空位的辅助下,La与N物种可从载体自发迁移至Co纳米颗粒表面,形成氮缺陷的亚氮化物覆盖层,实现对Co颗粒的部分包覆。基于从头算原子热力学分析进一步证实,这种连续的亚氮化物包覆层在反应条件下远比分立的La单原子吸附物种更稳定,确定了此前实验中观测到的从LaN载体迁移到Co催化剂表面上的物种为亚氮化镧物种(图3)。
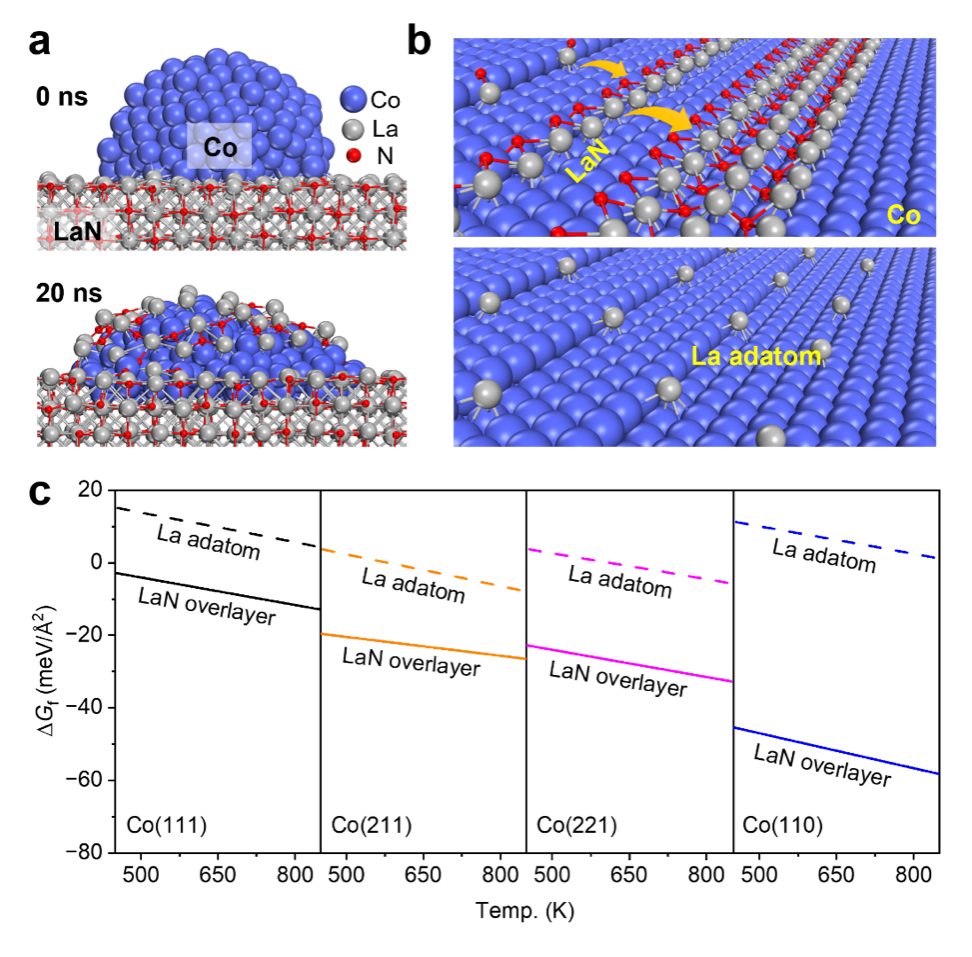
图3. LaN包覆Co的分子动力学模拟及热力学计算
研究发现,亚氮化物包覆Co的结构形成了独特的界面活性位点:由低价La阳离子与相邻的富电子Co位点构成的双功能位点,从根本上重塑了氨合成反应的势能面。该界面位点一方面显著强化了氮气的吸附与活化,另一方面适度弱化了氢的吸附强度,从根源上抑制了纯Co表面的氢中毒效应,解决了氨合成催化中经典的“氮气活化-氢中毒”权衡难题。微动力学模拟结果显示,该包覆结构催化氨合成的表观活化能仅为50 kJ·mol⁻¹,远低于纯Co催化剂的146 kJ·mol⁻¹,与实验测量值高度吻合。同时,包覆结构从物理上限制了Co纳米颗粒的迁移与团聚,赋予了催化剂优异的抗烧结稳定性,完美解释了实验中观测到的小尺寸催化剂长周期运行稳定性。
该工作提出的SMMI包覆判据具有优异的普适性,对LaN、CeN等氮化物负载Co、Ni等金属的经典高活性体系,均能准确预测其包覆效应的发生,同时合理解释了不同金属体系的活性差异,为催化剂的理性筛选提供了精准的理论标尺。此外,该统一理论框架还完整解释了氮同位素标记、X射线光电子能谱等一系实验现象,是目前该领域唯一能全维度自洽解释所有已知实验现象的统一理论框架,为氮化物基合成氨催化剂的研究提供了自洽、完整的物理图像。
该研究首次将研究团队前期建立发展的金属催化剂的稳定性理论、金属-载体作用理论、以及动态包覆理论从氧化物体系完整拓展至氮化物体系,破解了长期以来氮化物负载金属催化剂活性起源的核心争议,建立了从热力学预测、动态结构演化到催化机制解析的完整理论体系。该工作为温和条件下高效稳定合成氨催化剂的设计提供了全新的理论指导,为多相催化领域核心基础概念的发展与催化剂理性设计范式的升级,开辟了全新的方向,对推动绿色合成氨技术创新性发展、助力“双碳”目标实现具有重要的科学价值与应用前景。
论文第一作者为罗杰博士,通讯作者为李微雪教授。该工作得到了国家自然科学基金、国家重点研发计划、中国科大前沿重大研究项目、量子科学与技术创新计划、中国博士后科学基金等项目的资助,相关计算工作得到了中国科学院机器人AI-Scientist平台、中国科大超算中心的大力支持。
(化学与材料科学学院、精准智能化学全国重点实验室、合肥实验室,科研部)
3、厦门大学:光子晶体中紧束缚耦合的可编程调控
近日,易骏教授课题组在光子晶体物理与拓扑光子学方向取得新进展。研究团队提出了一种基于光子晶体周期性缺陷阵列的“可编程”耦合网络新方案,成功实现了对紧束缚模型中相邻格点耦合强度与符号的独立、精准调控,从而在微纳尺度上高保真地复现了紧束缚模型能带形成及多种拓扑物理现象。相关成果以“Tailored Tight-Binding Couplings in Photonic Crystals”为题在线发表于 Laser & Photonics Reviews。
紧束缚模型是凝聚态物理中理解能带结构与拓扑效应的核心理论框架之一。该模型将体系哈密顿量描述为格点上的本征能级与格点间跃迁耦合的组合。其中,耦合的大小决定能带展宽与色散尺度,而耦合的相对符号及相位分布则主导波函数的干涉性质与对称性约束下的能带演化,可引发能带反转、有效规范场以及拓扑边缘态等一系列关键物理现象。
然而,在光子晶体等工作在波长尺度的体系中,实现理想的紧束缚模型仍面临诸多挑战。一方面,光波具有显著的空间延展性,格点间不可避免地存在长程耦合与串扰,使得最近邻主导的紧束缚近似容易被破坏;另一方面,光学耦合的符号往往受限于模场固有的宇称对称性,难以实现像理想紧束缚模型中那样可预测、可编程的参数设计。如何在光学体系中构建真正满足紧束缚模型且高度可控的“光学格点网络”,一直是该领域亟待突破的难题。
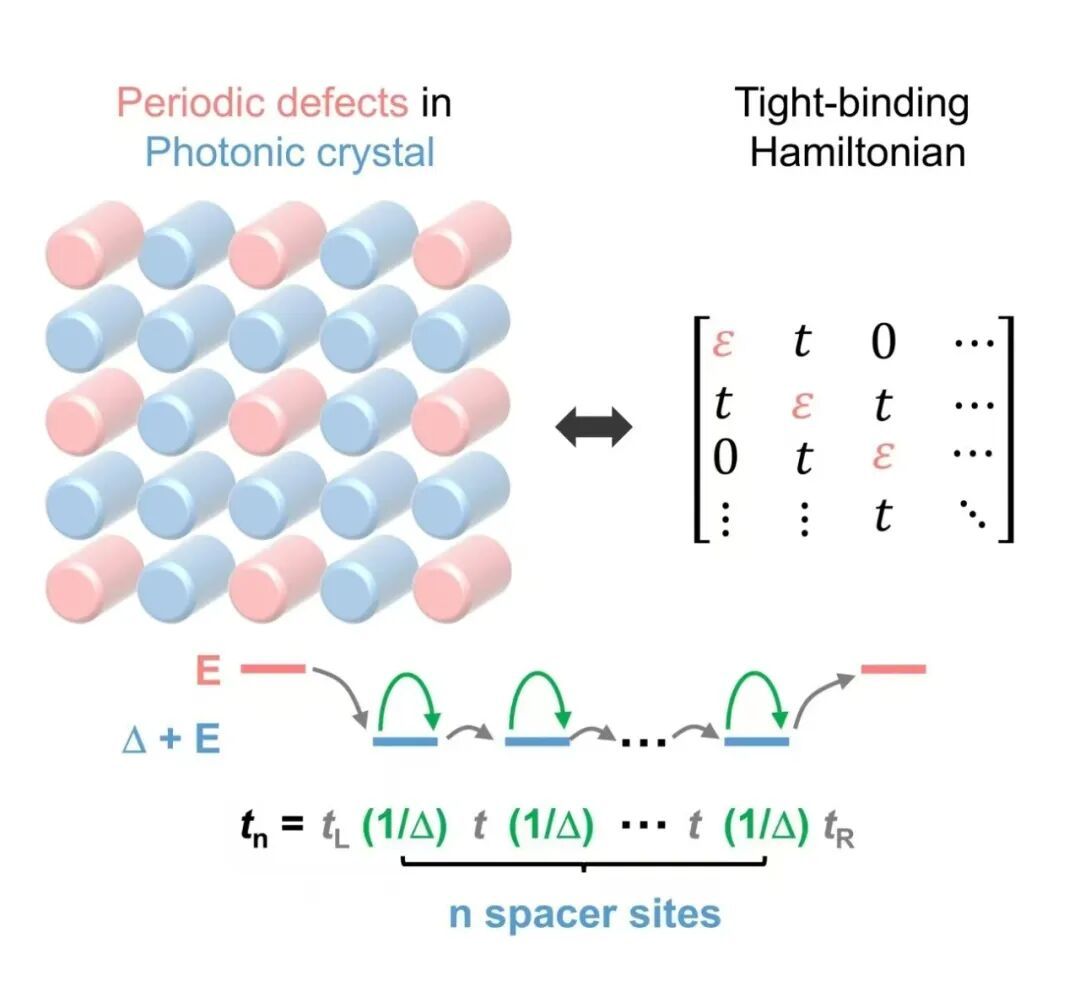
针对这一挑战,团队在前期光子晶体研究(Phys. Rev. Lett., 135, 083803,2025)的基础上,进一步提出了基于“缺陷调控超晶格”的新策略。该方案在具有光子带隙的背景晶格中引入周期性缺陷,利用带隙对光场的强局域效应,将缺陷模式塑造为彼此隔离的“人工原子”,并通过倏逝场隧穿实现最近邻耦合,从而使体系天然满足紧束缚模型条件。更关键的是,通过设计缺陷间的“间隔单元”参数,可以像“搭积木”一样对耦合强度与符号进行自由编程。这相当于让光在若干“中介单元”传输,多级中介的干涉与失谐共同决定最终等效耦合的幅度与相位。
基于该平台,团队成功构建了二维SSH拓扑晶格及具有合成磁通的光子晶体结构,并在数值模拟中获得与紧束缚模型高度一致的能带与边界态特征,包括拓扑相变及莫比乌斯(Möbius)型边界态等现象。该研究提出了一种纯介质、可扩展且参数可编程的光子晶体设计思路,为在波长尺度实现拓扑物态、合成规范场以及片上光学器件设计提供了新的路径,未来有望推广至更丰富的晶格类型与更高维度的等效模型构建。
该论文的第一作者为厦门大学电子科学与技术学院博士研究生郑俊榕,通讯作者为易骏教授。研究工作得到香港大学马静文博士及厦门大学田中群院士的指导与协助。本研究受国家重点研发计划(2021YFA1201502)、国家自然科学基金(22522309、22272140)、福建省自然科学基金(2025J09013)、中央高校基本科研业务费(20720240068)以及香港研究资助局项目(GRF 17208725)资助。
4、上海交大计算机学院智能软件与系统研究所OASIS课题组再获国际存储顶会USENIX FAST最佳论文奖
近日,第24届USENIX文件与存储技术大会 (24th USENIX Conference on File and Storage Technologies, 简称 USENIX FAST) 在美国加州圣克拉拉召开。上海交通大学计算机学院智能软件与系统研究所OASIS课题组凭借论文《Here, There and Everywhere: The Past, the Present and the Future of Local Storage in Cloud》脱颖而出,荣获大会最佳论文奖 (Erik Riedel Best Paper Award)。这是该课题组继2023年获得中国首篇FAST最佳论文奖后,再次问鼎这一存储领域的最高荣誉。该研究由上海交通大学、阿里云及Solidigm科研团队共同完成,博士生杨乐平为第一作者,薛广涛教授与徐尔茨副教授共同指导。

图:FAST 2026 最佳论文奖证书
破局“不可能三角”:云本地存储的十年进化
在云计算领域,云本地存储(Local Storage)虽具备极致性能与成本优势,但在NVMe SSD性能飞速演进的今天,传统架构正面临CPU资源争用、开销过大及扩展性差等瓶颈。此外,本地磁盘天然缺乏“高可靠性”与“弹性扩容”能力,难以支撑大语言模型(LLM)等新兴场景的严苛需求 。本论文首次系统性地披露了阿里云本地存储过去十年间经历的三代架构演进:l Espresso(第一代)软件优化:引入用户态SPDK与轮询机制,减少上下文切换。l Doppio(第二代)硬件加速:利用商用ASIC DPU实现硬件卸载,彻底释放宿主机CPU算力。l Ristretto(第三代)软硬结合:采用ASIC与SoC协同设计,实现单盘带宽6GB/s,单实例IOPS高达720万,直逼物理盘极限。
面向未来:Latte 架构引领云存储新范式
针对本地磁盘缺乏可靠性的固有痛点,OASIS课题组与阿里云联合提出了前瞻性的混合架构——Latte (Local-Cloud Combined Storage) 。Latte 架构的核心突破点在于:1. 冷热分层:巧妙将高性能本地磁盘(Ristretto)作为前端缓存,配合低成本弹性块存储(EBS)作为后端,化解了性能与可用性的矛盾。2. 智能调度:引入轻量级机器学习(ML)调度器与高效缓存机制(S3-FIFO),显著降低读写延迟。3. 极致性价比:生产环境评测显示,Latte的读命中率超82%,在提供媲美极高性能云盘(EBSX)体验的同时,成本仅为其 1/10至1/5。
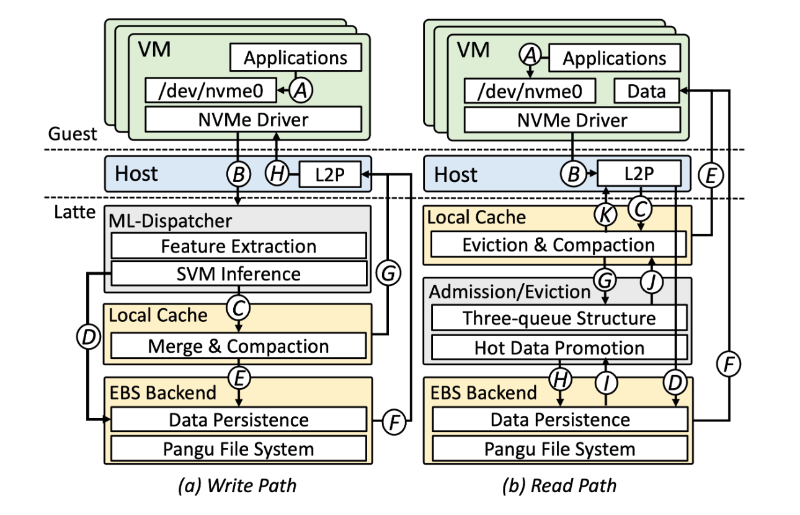
图:Latte本云混合架构
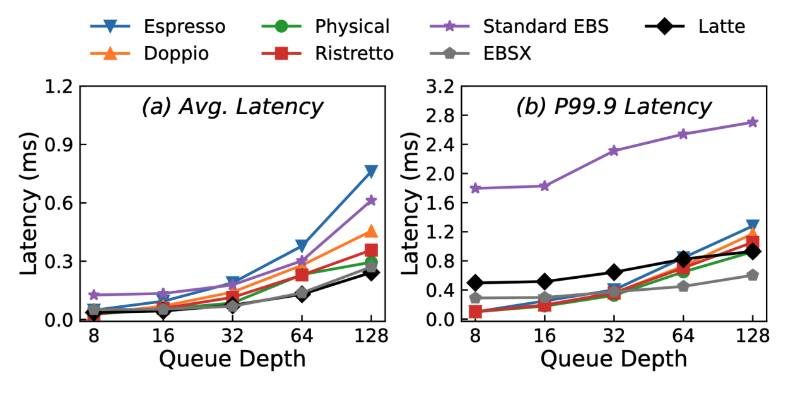
图:Latte混合架构
超低延迟性能产学研结合,定义全球存储新标准USENIX FAST 作为存储领域的国际顶级学术会议(CCF A类),以极高的录用难度著称。2026年大会从全球投稿中仅录用44篇论文(录用率17.4%),其中仅有两篇获评最佳论文。此次获奖不仅彰显了上海交大OASIS课题组在底层系统结构领域的深厚造诣,也证明了我国在“产学研深度融合”模式下的国际领先竞争力。该研究为全球大规模云存储基础设施的演进提供了宝贵的“中国方案”与实践经验。关于OASIS实验室:上海交通大学OASIS课题组(Operating And Storage Infrastructure System)长期聚焦操作系统、分布式存储及网络前沿研究,近年来在OSDI、SOSP、FAST、Eurosys、ATC等国际顶会上频传捷报,持续攻克工业界底层核心技术难题 。 作者: 计算机学院 供稿单位: 计算机学院(网络空间安全学院、密码学院)
