

前几天,DeepSeek 被曝出在春节前后发布新一代旗舰模型 DeepSeek-V4。
据称 V4 在代码任务上的表现已超越 Anthropic 的 Claude 系列以及 OpenAI 的 GPT 系列。
虽然官方仍保持神秘,但 DeepSeek 近期密集发布的论文或许已经初现端倪。
就在昨晚,DeepSeek 联合北京大学 发布了一篇名为《Conditional Memory via Scalable Lookup》的新论文, 梁文锋也再次署名。

Engram 或许是 V4 强大能力的「技术底牌」之一。
那它能否验证传闻:V4 在处理超长代码项目和复杂逻辑推理上取得了重大突破,且解决了模型越练越「糊涂」的性能衰退难题?
论文传送门:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
你的大模型,其实一直在「笨拙」地计算
当你问 ChatGPT「莎士比亚的全名是什么」时,它并不是从某个知识库里直接调取答案。相反,它需要动用多层神经网络,通过复杂的矩阵运算,逐层「拼凑」出这个答案。
论文用了一个更具体的例子:当模型遇到「Diana, Princess of Wales」时,需要消耗前 6 层网络才能完成识别。第 1 到 2 层只能理解这是「Wales」,第 3 层才意识到这是「Princess of Wales」,直到第 6 层才最终确认这是「戴安娜王妃」。
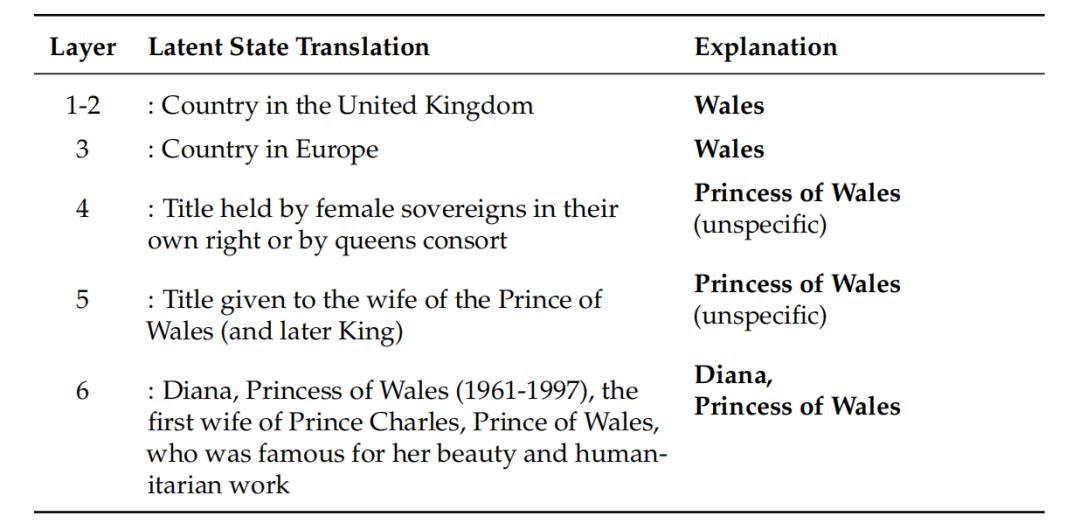
DeepSeek 的研究员在 Engram 论文中指出:这种靠「深度计算」来模拟「记忆检索」的过程,极大地浪费了模型宝贵的脑力(推理能力)。
如果 V4 真如爆料所说「代码能力吊打全场」,那么它一定解决了这个问题——因为代码中包含大量固定的语法和套路,没必要每次都去「推理」一遍。
给 AI 挂上「超级字典」
为了解决这个问题,DeepSeek 在论文中进行了一波「技术复古」。
既然有些知识是固定不变的,为什么不直接把它们存储起来,需要时直接查询,而不是每次都重新计算?
他们把 NLP 领域最古老的 N-gram(N元语法) 请了回来,并改造成了现代化的 Engram 模块 。
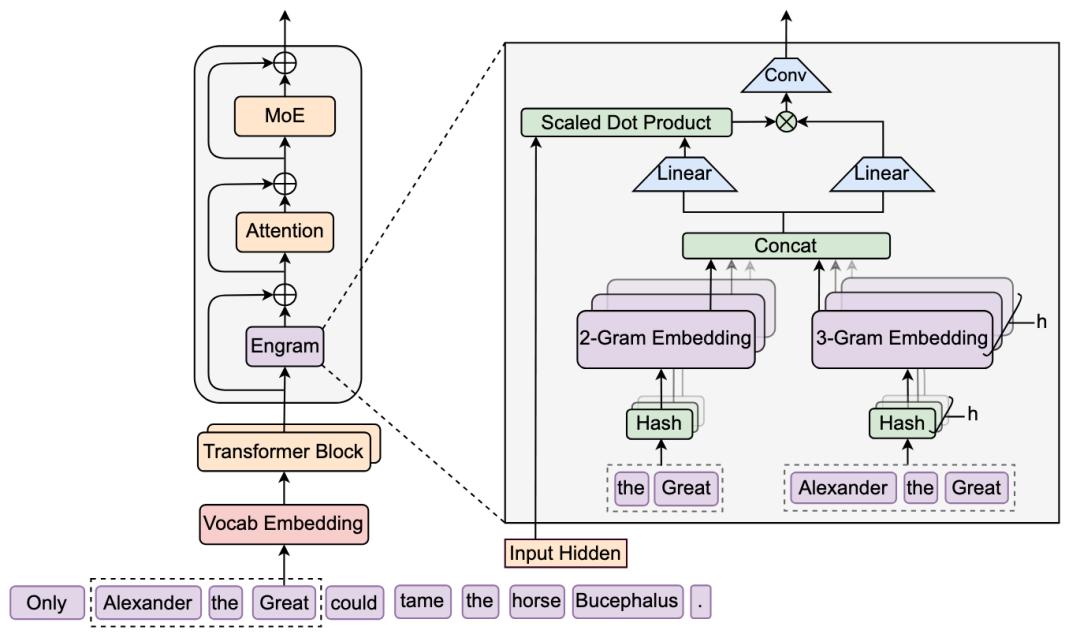
它通过哈希函数将局部上下文映射到一个巨大的嵌入表中。当模型遇到「Alexander the Great」这样的固定短语时,不再需要多层网络逐步理解,而是直接从记忆库中提取对应的语义向量。
为了处理「不同词汇映射到同一位置」和「同一词汇在不同语境下意义不同」带来的干扰,团队引入了上下文感知的门控机制(Context-aware Gating)。用当前的隐藏状态作为查询向量,对检索结果进行动态调制。如果检索到的内容与当前上下文不匹配,门控值会接近零,有效抑制噪声。
在处理「Only Alexander the Great could tame the horse Bucephalus」这句话时,Engram 的门控激活热力图显示,模型在遇到「the Great」和「Bucephalus」时出现明显的激活峰值,说明它成功识别并检索了这些固定实体的语义表示。

这或许解释了为什么 V4 的代码能力会大幅提升: Engram 就像是给程序员配了一个超级 IDE,自动补全了所有的固定语法,让模型的大脑只需要专注于「如何解题」,而不是「怎么写分号」。
把 CPU 内存条变成「显存」
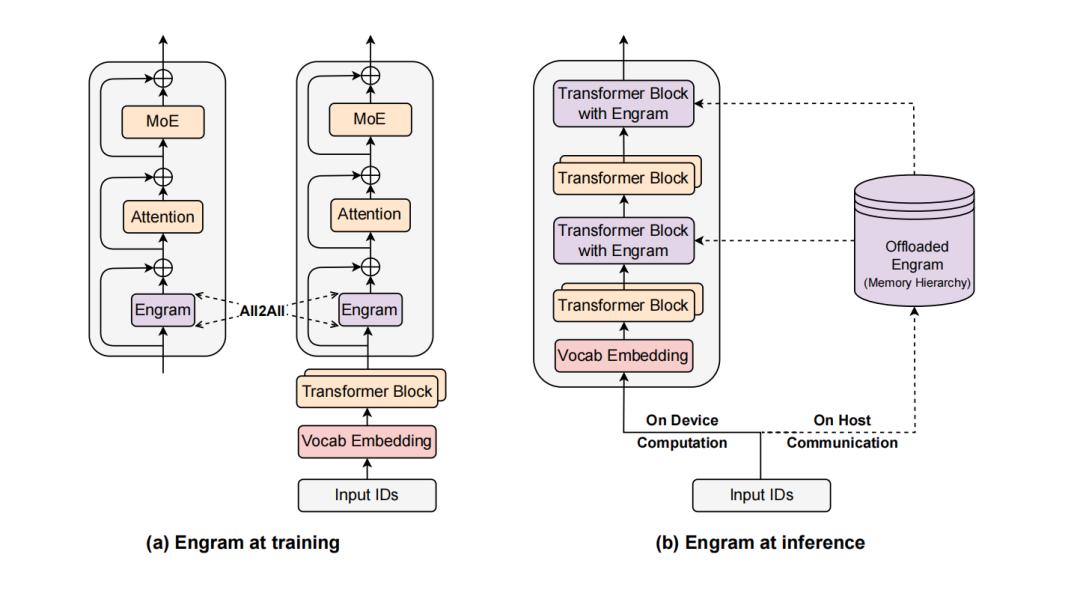
除了让模型变聪明,Engram 这篇论文里最让开发者和中小企业兴奋的是:GPU显存不再是模型规模瓶颈 。DeepSeek 正在尝试 用便宜量大的 CPU 内存(DRAM),去替代昂贵稀缺的 GPU 显存(HBM)。
传统的 MoE 模型是动态路由的,模型必须算完这一层,算出结果数值,才能决定下一层该去哪个专家那里计算。这叫「走一步看一步」,数据根本来不及提前准备。
而 Engram 的检索逻辑则完全由输入 token 序列决定。一旦看到输入文本,就能立即计算出需要访问哪些嵌入向量,无需等待中间层的计算结果。
这种「计算与传输重叠(Overlap)」的技术,完美掩盖了 CPU 内存读取慢的缺陷。
实验证明了这一策略的可行性。他们构建了一个 1000亿参数(100B) 的巨型 Engram 词表,并且把这部分参数完全扔到了 CPU 内存里(注意,一点都不占用宝贵的显存)。
在实际推理测试中,相比于纯 GPU 运行,整体吞吐量的损耗竟然小于 3%,这在工业部署中几乎可以忽略不计。
以前你想跑千亿参数模型,可能需要几张 A100 (80G)。现在,你可能只需要一张消费级显卡负责计算,再插上几根便宜的 64GB 内存条负责存知识,就能跑起来。
这下不用担心英伟达、AMD 在 2026 年上调 GPU 价格了。
还想让模型学会最新的法律条文或医疗数据?不需要重新训练庞大的神经网络,只需要在 CPU 内存里「外挂」一个新的 Engram 表。对于垂直行业应用,这意味着维护成本的指数级下降。
因为语言符合二八定律,常用的词很少,未来的 DeepSeek 模型可能会这样运行:热知识放在 GPU 显存光速响应,温知识放在 CPU 内存毫秒级预取,冷知识甚至可以放在固态硬盘里。这意味着,原本只能存几百亿参数的硬件,理论上可以外挂几万亿参数的超大知识库,而且成本极低。
过去我们认为模型规模受限于 GPU 集群的显存总量,Engram 证明了只要设计得当,廉价的主机内存也能成为模型容量的有效载体。这为未来的超大规模模型部署打开了新的可能性。
实验数据验证 V4 传闻
回到 V4 的爆料,The Information 提到新模型在「长代码处理」和「逻辑条理性」有质的飞跃。有趣的是,Engram 论文里的实验数据印证了这个说法。
在知识密集型任务上,Engram-27B 相比 MoE-27B 在 MMLU 上提升 3.4 分,CMMLU 提升 4.0 分。这符合预期,毕竟 Engram 本就是为知识检索设计的。
但真正出人意料的是推理能力的飞跃。在 BigBench Hard 上提升了 5.0 分,ARC-Challenge 提升 3.7 分,DROP 提升 3.3 分。代码和数学领域同样显著,HumanEval 提升 3.0 分,MATH 提升 2.4 分,GSM8K 提升 2.2 分。
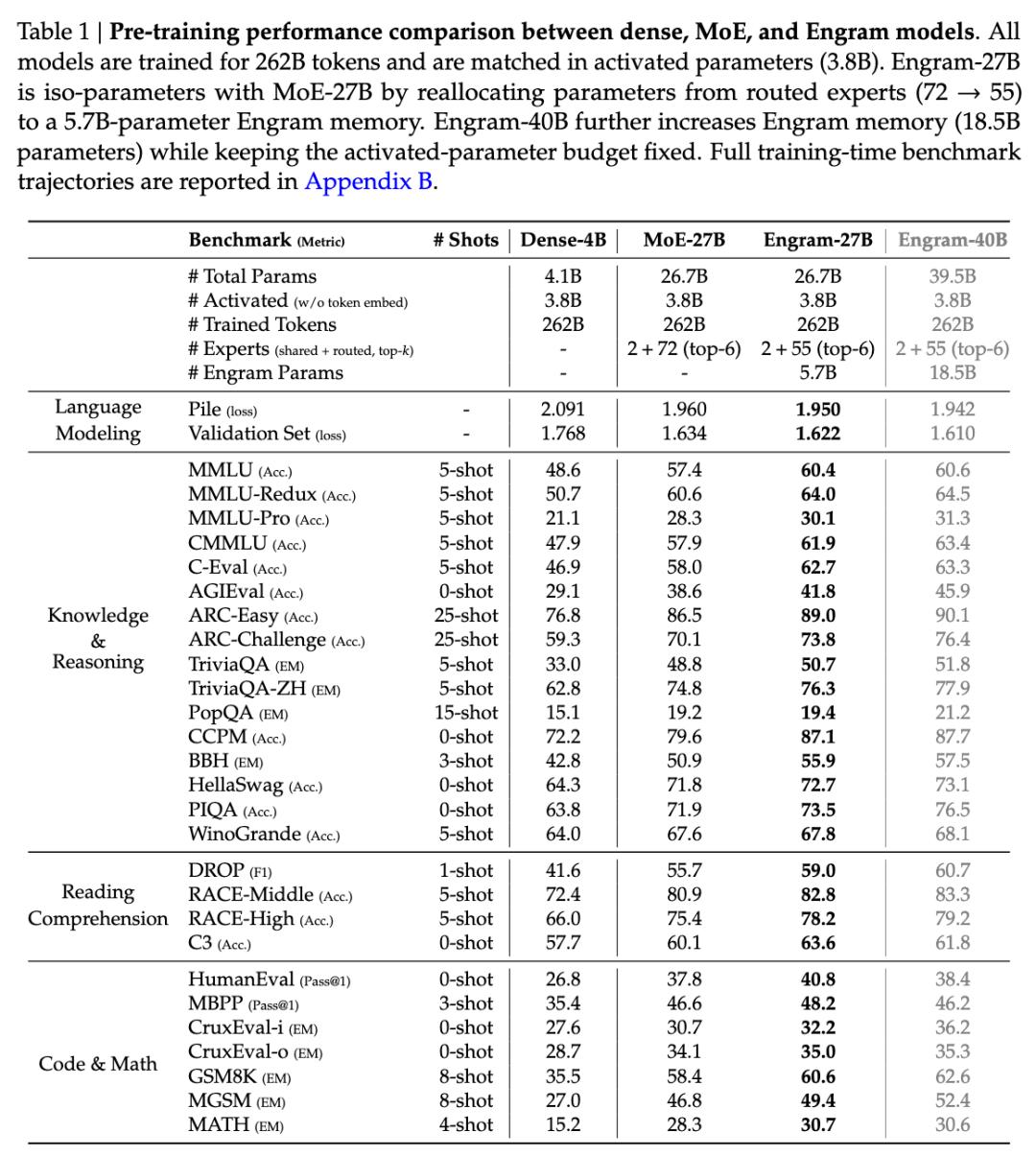
长文本能力的提升同样惊人。在 32k 上下文窗口的 RULER 基准测试中,Engram-27B 在多查询 Needle-in-a-Haystack 任务上的准确率从 84.2% 跃升至 97.0%,变量追踪任务从 77.0% 提升到 89.0%。这是因为通过查询处理局部依赖,注意力机制被解放出来专注于全局上下文建模。
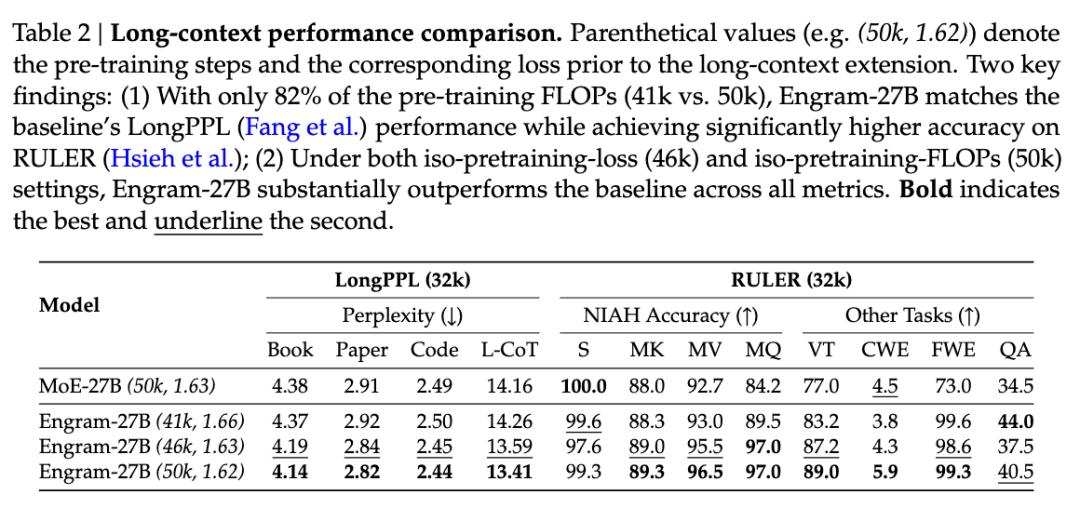
通过对模型内部的「CT 扫描」,研究人员发现:因为 Engram 在浅层就搞定了死记硬背的工作, 模型原本被占用的深层网络被「解放」了 。这就像把背书的时间省下来,全拿去刷奥数题,智商能不涨吗?这与爆料中提到的「V4 回答更有条理、推理更强」不谋而合。
DeepSeek 的野心不止于「大」
从 R1 的 86 页技术报告,到 mHC 架构,再到今天的 Engram 记忆模块,DeepSeek 的节奏明显加快。
如果说 OpenAI 在探索 Scale Law(规模定律)的极限,那么 DeepSeek 似乎正在疯狂挖掘 Architecture Efficiency(架构效率) 的金矿。他们希望用更巧妙的结构让模型「吃得少、干得多」。
春节 将至,DeepSeek V4 是否会带着这些「硬核技术」再次血洗榜单?
让我们拭目以待。至少从这篇论文来看,他们的「军火库」里,确实还有不少好东西。
