

针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。
不仅无需昂贵的长上下文训练,就能实现无缝零样本上下文扩展;
且用DroPE重新校准模型所需预训练预算不到1%。
这项技术被网友调侃为“NoRoPE”(没有旋转位置编码)。
原因很简单,因为DroPE可以看作是一种丢弃位置嵌入来扩展上下文的方法。

那是怎么个“丢弃”法呢?
把位置嵌入当成临时训练工具
首先咱得先来搞懂什么是位置嵌入。
在Transformer模型中,有一种核心机制叫自注意力(Self-Attention),它能够让模型在读到一个词时关联到其他词,搞清楚谁和谁有关系。
但是,这种机制在并行计算时,会丢失文本序列原本的前后位置关系。
比如说,在这个机制中,“猫抓老鼠”和“老鼠抓猫”在计算上是一样的,这样大模型就分不清到底应该把谁放前边。

为了让模型清楚地知道谁在前谁在后,研究人员引入了位置嵌入(Positional Embedding)。
现在最流行的位置嵌入方法是RoPE(旋转位置编码),可以把它想象成一个句子指南针,能够帮助模型快速建立起对语序的感知,分清前后关系,让训练过程更稳定。
但是,RoPE在长序列处理方面存在严重缺陷,RoPE中的高频维度会因旋转角度快速饱和,导致位置编码失效;低频维度则因旋转角度变化过慢,同样无法准确表征位置信息。

而DroPE正解决了这一问题。
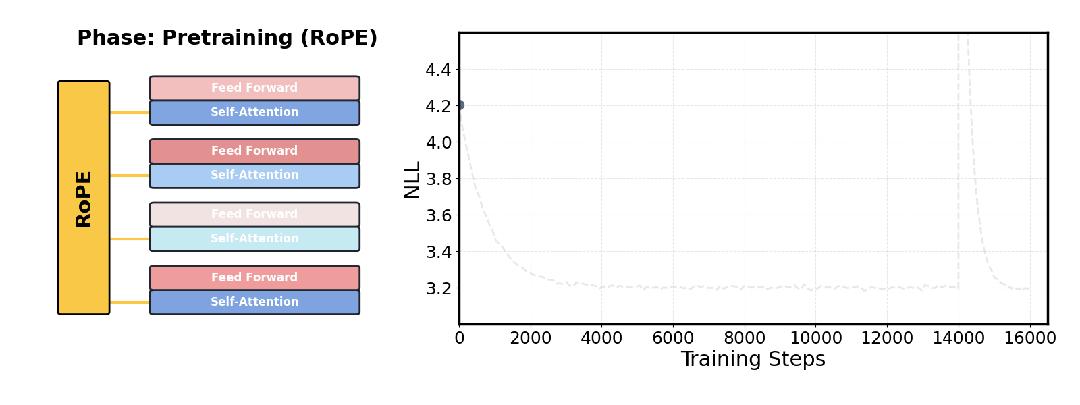
它把RoPE当成临时的训练工具。
在预训练阶段,借助RoPE来保证训练的稳定性和效率,为模型提供可学习的顺序感。
而到了推理阶段,则大胆地丢弃位置嵌入,并在原上下文长度下进行简短的重新校准。
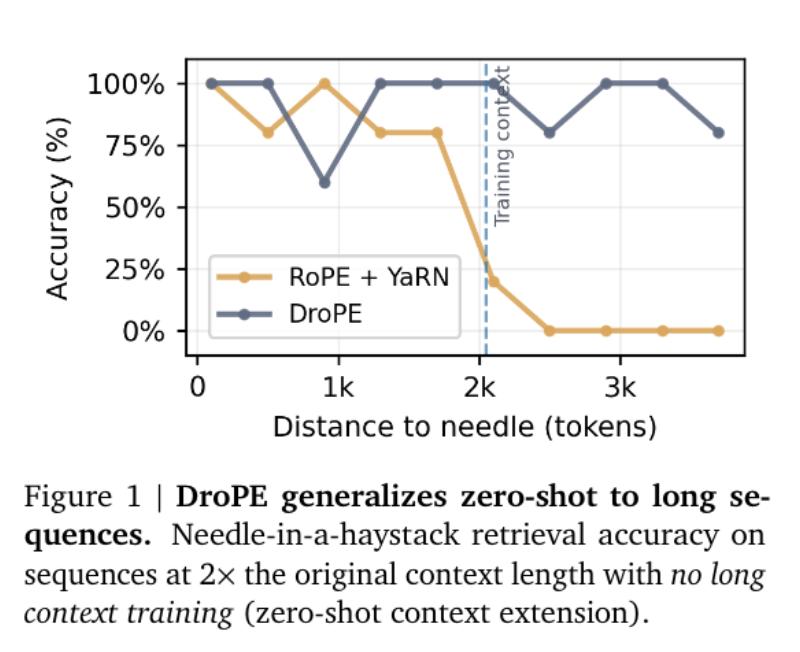
DroPE通过这种方式,成功解锁了模型的长上下文外推能力,实现了零样本扩展。
在不针对长文本进行额外训练的情况下,让模型能够处理更长的序列。
研究团队在多个模型上进行了实验,包括从零开始训练的5M参数模型、SmolLM家族模型(360M/1.7B)以及7B参数的Llama2-7B等。
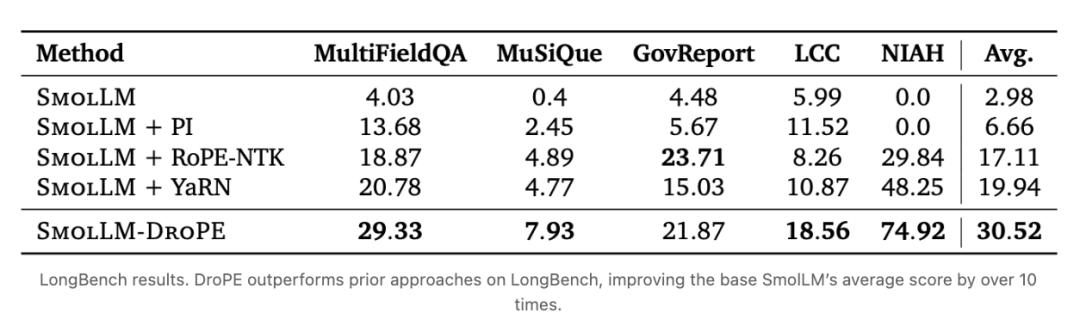
在LongBench基准测试里,DroPE将基础SmolLM的平均得分提高了10倍以上。
在NIAH任务评估中,DroPE模型的召回率高达74.92%,大幅超越了传统的RoPE缩放方法。
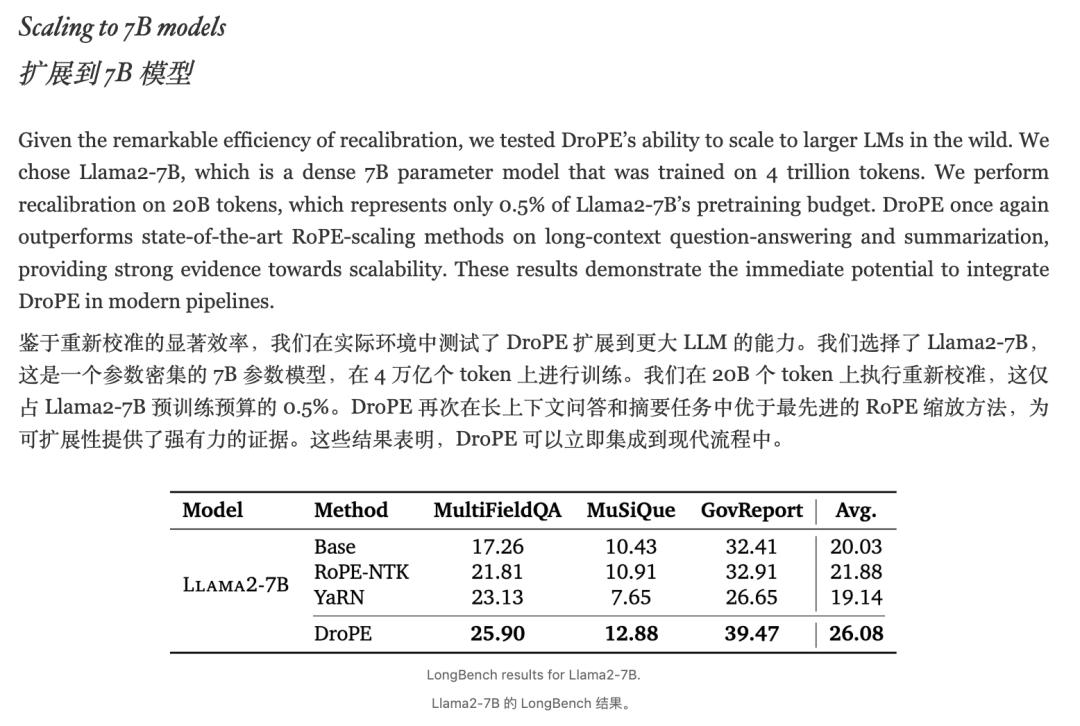
即使在大规模的Llama2-7B模型上,仅使用0.5%的预训练预算进行重新校准,DroPE也能在长上下文问答和总结任务中展现出卓越的性能。
Sakana AI
提出DroPE技术的团队,来自Transformer八子之一Llion Jones和前谷歌高级科学家David Ha创办的Sakana AI。

听起来是不是有点熟悉?
不仅被英伟达老黄投资过,这家公司还造出了首个“出道”自带10篇完整学术论文的AI科学家The AI Scientist,由此走入了大家的视野。

就在前几天,Sakana还发布了一项有意思的研究。
它们和MIT研究团队一起提出了数字红皇后(Digital Red Queen)算法,借助大语言模型在经典编程游戏《Core War》中实现对抗性程序进化。
新程序需要击败所有前代程序以模拟红皇后动态。

实验显示,经多轮迭代,生成的“战士”代码不仅对人类设计的程序表现出更强通用性,还出现表型趋同、基因型多样的“趋同进化”现象,且能减少循环相克问题。
或许,这项研究还能为网络安全、药物设计这类需要互相抗衡的领域提供参考。
DroPE论文地址:https://arxiv.org/abs/2512.12167
代码地址:https://github.com/SakanaAI/DroPE
参考链接:https://x.com/SakanaAILabs/status/2010508366574186825
DRQ论文地址:https://arxiv.org/abs/2601.03335
