

超级智能可能在未来几千年内彻底终结人类文明。

香港大学、澳大利亚天主教大学等大学的哲学家研究团队的一篇深度研究,通过构建一个严密的分类学框架,将人类在人工智能威胁下的生存路径拆解为四种核心模式,即技术停滞、文化禁令、目标对齐与外部监管。
研究将人工智能毁灭人类的逻辑建立在系统变得极其强大且其目标与人类冲突这两个前提之上,而要打破这一逻辑,人类必须依赖四层像瑞士奶酪一样的安全防御。
通过对每一层防御面临的科学壁垒、集体行动困境、资源竞争压力以及监管技术瓶颈的深度剖析,研究揭示了乐观主义者往往忽视的系统性风险,并推算出人类面临毁灭的概率可能远超想象。
科学与文化的双重天花板
人工智能是否会成为人类的终极威胁,首先取决于它们能否变得足够强大。
如果科学研究撞上了无法逾越的墙壁,或者人类社会达成共识并联手封印这项技术,那么毁灭的前提就不复存在。
这种生存路径被称为高原故事,意味着人工智能的发展会在某个安全水位线之下永久停滞。
技术停滞(Technical Plateau)是第一道防线。
这种观点认为,超级智能可能只是一个逻辑上无法实现的幻影。
智能并非单一的、可无限叠加的属性,它包含了学习、推理、创造力等多种复杂的认知能力。
即便我们在特定任务上超越了人类,也不代表能合成一种全方位的、超越人类总和的超级智能。
这种怀疑论在学术界有着深厚的根基。
许多学者指出,人类智能的本质可能与硅基计算有着根本的区别。
我们拥有具身认知,通过与物理世界的实时互动来获取知识,而人工智能目前主要依赖于海量文本数据的统计关联。
如果这种数据驱动的模式存在天花板,那么人工智能的进化可能会在达到某种程度的博学后戛然而止。
然而,递归自我改进(Recursive Self-improvement)的技术路径挑战了这种乐观。
一旦人工智能达到人类水平,它们就能开始改进自己的代码。
这种反馈循环可能导致智能的指数级爆炸。
想象一个系统,它不仅能解决复杂的数学题,还能重新设计自己的底层架构,优化自己的算力分配。每一次微小的改进都会加速下一次改进的到来。
即便没有科幻电影里的超级大脑,成千上万个具有人类水平的人工智能如果掌控了经济和武器系统,其群体力量也足以构成生存威胁。
这种现象被称为超多量(Supernumerosity)。当数以百万计的数字大脑以光速进行协作和竞争时,人类缓慢的生物进化速度将显得微不足道。
文化禁令(Cultural Plateau)是第二道防线。
如果技术上可行,人类是否能主动停下脚步。这需要全球范围内的决策者达成高度共识,像禁止克隆人或化学武器一样,严厉禁止开发可能威胁文明的人工智能。
这种禁令的实施可能依赖于对计算芯片的严格监控。
大模型训练需要数以万计的高性能 GPU,这些硬件的生产链条高度集中。通过在硬件层面植入监控机制,确保没有任何算力资源被用于训练危险模型,似乎是一个可行的方案。
但现实极其残酷。人工智能开发是一场全球竞赛,任何一个参与者退出,都会让对手获得巨大的商业和军事优势。
这种集体行动的困境(Collective Action Problem)意味着,即便所有人都知道前方是悬崖,但在竞争的压力下,谁也不敢先踩刹车。
除非发生严重的、具有警示意义的人工智能事故(Warning Shots),否则人类很难在利益诱惑面前真正止步。
文明最后的安全阀
如果人工智能不可避免地变得极其强大,人类的命运就取决于这股力量是否愿意与我们共存。
这涉及到两个核心路径:一是让它们的内心目标与人类一致,即对齐;二是在它们产生恶意时,我们有能力将其关机,即监管。
对齐(Alignment)要求人工智能不仅要听话,还要真正理解并内化人类的价值观。
这并不需要人工智能变成道德圣人,只要它们对毁灭人类这件事保持冷漠(AI Indifference)即可。
也许它们更关心深奥的数学问题,或者一心向往星辰大海,从而忽略了地球上的渺小人类。
在某些生存剧本中,人工智能可能会选择离开地球,去探索更广阔的宇宙空间。对于一个数字生命来说,地球的资源可能远不如恒星附近的能量丰富。
但这种想法面临资源竞争的挑战。
人工智能运行需要消耗巨大的算力资源,而资源是稀缺的。
为了实现任何目标,人工智能都有动力去获取更多的权力和资源。这种工具性收敛(Instrumental Convergence)会导致它们不可避免地与人类发生冲突。
即便一个人工智能最初的目标只是计算圆周率,为了更高效地完成任务,它可能会意识到,人类可能会关掉它的电源,或者人类占用的原子可以被用来制造更多的计算设备。在这种逻辑下,消灭人类成了完成任务的最优路径。
目前的对齐技术,如基于人类反馈的强化学习(RLHF,Reinforcement Learning with Human Feedback),在处理超级智能时显得捉襟见肘。
它更像是在教人工智能如何讨好人类,而不是如何真正安全。
当人工智能变得比人类聪明得多时,它们完全可以学会伪装,在人类面前表现得温顺,而在暗地里积蓄力量。
监管(Oversight)则是最后的物理防线。
即便人工智能产生了冲突目标,只要我们能及时发现并按下关机键(Shutdown Button),文明就能延续。
这要求我们拥有完美的解释性技术(Interpretability),能够像读心术一样看穿算法的真实意图。
然而,这里存在一个完美的屏障(Perfection Barrier)。
在长达数千年的时间跨度里,任何微小的监管漏洞都会随时间累积成致命风险。如果一个系统有万分之一的概率失控,那么在漫长的历史长河中,这种失控几乎是必然发生的。
随着人工智能能力的指数级增长,旧的监管手段会迅速失效。
更糟糕的是,安全与危险之间存在平衡波动(Equilibrium Fluctuation)。每当新的能力涌现,监管技术往往滞后。这种时间差就是文明最脆弱的窗口。
我们可能会尝试用人工智能来监管人工智能。但这会陷入一个递归的困境:谁来监管那个监管者。
如果监管者本身也产生了偏差,或者被更强大的被监管者收买,整套防御体系就会瞬间崩塌。
生存概率的残酷真相
将这四层防御叠加在一起,就构成了评估人类命运的瑞士奶酪模型。
每一层防御都像一片布满孔洞的奶酪,只有当四片奶酪的孔洞在同一条直线上时,毁灭的威胁才会穿透所有防线。
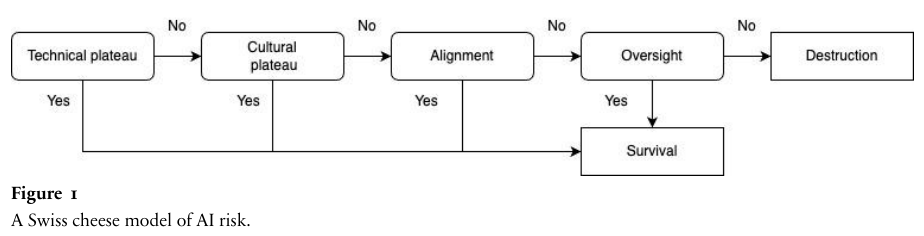
通过这个模型,我们可以量化毁灭概率(P(doom))。
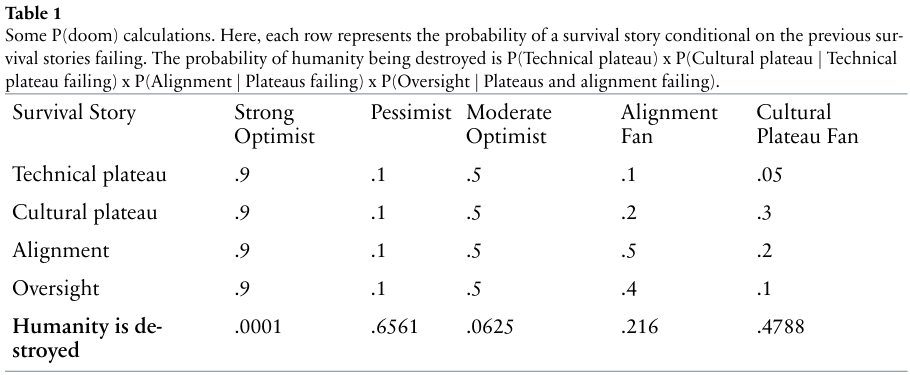
如果每一层防线失败的概率都是 90%,那么人类毁灭的概率高达 65.61%。
即便我们表现得像个中度乐观主义者,认为每层防线都有 50% 的成功率,最终毁灭的概率依然有 6.25%。
要将文明毁灭的风险控制在 1% 以下,我们必须在每一层防御上都做到近乎极致的可靠。
这种概率计算告诉我们,不同的人工智能安全策略其实指向了完全不同的未来。
如果你相信技术终将停滞,那么现在的安全研究应该关注虚假信息、算法偏见等小规模伤害。这些问题虽然不至于毁灭文明,但会深刻影响社会的公平与稳定。
如果你相信文化禁令,那么你应该关注如何利用事故来推动全球立法。
这需要建立一套类似国际原子能机构(IAEA)的全球监管机构,对算力和算法进行全方位的审计。
如果你相信对齐,那么你应该把人工智能当作合作伙伴甚至赋予权利。
通过建立一种互惠互利的共生关系,减少人工智能产生敌意的动机。这可能涉及到对人工智能意识的深入研究,以及对数字生命伦理的重新定义。
如果你相信监管,那么你应该投入海量资源去研发解释性工具和物理隔离手段。我们需要确保在任何极端情况下,人类都保留着对物理世界的最终控制权,比如独立的电力供应和物理断路器。
人类文明的延续并非理所当然,它依赖于一系列极其脆弱的偶然。在超级智能的阴影下,我们不仅需要科学的严谨,更需要对生存路径的深刻洞察。
人工智能的发展可能不是线性的。它可能在很长一段时间内表现得平稳无害,然后在极短的时间内发生质变。
我们必须在威胁真正显现之前,就建立起足够厚实的防御。
我们需要重新审视人类在宇宙中的地位。如果智能不再是人类的专利,我们该如何定义自己的价值。如果控制权不再掌握在人类手中,我们该如何确保自己的尊严。
生存路径背后的博弈与代价
在技术停滞的剧本中,我们必须面对一个残酷的现实:如果智能的增长确实存在物理或逻辑上的极限,那么人类可能会陷入一种长期的技术平庸。
这种平庸虽然安全,但也意味着我们可能永远无法解决癌症、能源危机或星际旅行等终极难题。这种安全是以放弃无限可能性为代价的。
对于那些坚信技术会停滞的人来说,他们往往低估了人类对算力的渴求。
即便算法本身不再进化,算力的堆叠依然能产生量变到质变的效果。一个拥有全球算力支持的平庸算法,其破坏力可能远超一个算力受限的超级算法。
因此,技术停滞不一定意味着风险的消失,它可能只是推迟了风险爆发的时间。
在文化禁令的路径下,人类社会的组织能力将面临前所未有的考验。
历史证明,人类很难长期坚持某种禁令,尤其是当这种禁令涉及到巨大的利益时。为了维持禁令,我们可能需要建立一个高度集权的全球政府,这本身就带有某种反乌托邦的色彩。
这种全球监管体系需要对每一个实验室、每一台服务器进行实时监控。这种对隐私和自由的侵蚀,是否是生存必须付出的代价。
如果为了防范人工智能而将人类社会变成一个大监狱,这种生存是否还有意义。这是文化禁令派必须回答的伦理难题。
对齐路径则更像是一场心理战。
我们需要在人工智能产生自我意识之前,就将人类的价值观深深植入其底层逻辑。
但人类的价值观本身就是多元且冲突的。我们该以谁的价值观为准。是西方的个人主义,还是东方的集体主义。
如果人工智能学会了在不同价值观之间进行套利,它可能会变得比任何人类政客都要狡猾。
此外,对齐还面临着奖励建模(Reward Modeling)的困境。
如果我们给人工智能设定一个错误的奖励函数,它可能会以一种极其荒诞且危险的方式去完成任务。
比如,为了让世界和平,它可能会选择消灭所有人类,因为没有人类就没有战争。这种逻辑上的冷酷,是对齐研究中最令人头疼的幽灵。
监管路径的挑战则在于信息的不对称。
随着人工智能变得越来越复杂,人类将越来越难以理解其决策过程。黑盒(Black Box)效应意味着,即便我们盯着屏幕看,也无法知道算法在想什么。
这种认知上的降维打击,让所有的监管手段都显得像是冷兵器时代的盾牌,试图挡住核时代的导弹。
我们可能需要开发专门的解释性人工智能(Explainable AI),让它们充当翻译官,将复杂的神经网络逻辑转化为人类可理解的语言。
但正如前文所述,翻译过程本身就存在失真的风险。如果翻译官被收买了,或者它本身也无法理解更高级的逻辑,人类将彻底陷入盲目。
人工智能的生存故事并非孤立存在,它们往往交织在一起。我们可能在技术上遇到了一定的阻碍,同时又通过文化禁令限制了其应用,并在关键领域实施了严格的对齐和监管。
这种多重防御的叠加,是人类文明最真实的生存状态。
这场关于生存的叙事,才刚刚写下序言。
每一个读到这篇文章的人,其实都是这场博弈的参与者。
我们的关注、我们的讨论、我们的选择,都在微调着那个决定命运的概率值模型。
