

黄仁勋的预言成真!从Sora的梦幻视频到英伟达的3D通才模型,AI不再只是「看和说」,而是真正「动手」构建3D世界,开启机器人时代的无限可能。
黄仁勋没有吹牛!
AI不能只会看、会说、会生成,它还必须理解并遵守物理世界的规则。
现在,英伟达补上了关键拼图——
让AI从「生成画面」升级为「生成可行动的3D世界」,不仅能描述世界,还能一步步搭建世界、修改世界、纠错迭代。
时间拨回到两年前, 2024年2月。
OpenAI发布了一段「东京街头漫步」的Sora视频,震惊世界,硅谷集体狂欢。

人们高呼「现实不存在了」,仿佛人终于可以「言出法随」、重造万物。
但在一片喧嚣中,那个穿皮衣的男人始终保持冷静,甚至带有一丝不屑。
在2024年和2025年的多次演讲中,黄仁勋像复读机一样不断重复——「Physical AI」(物理AI)。
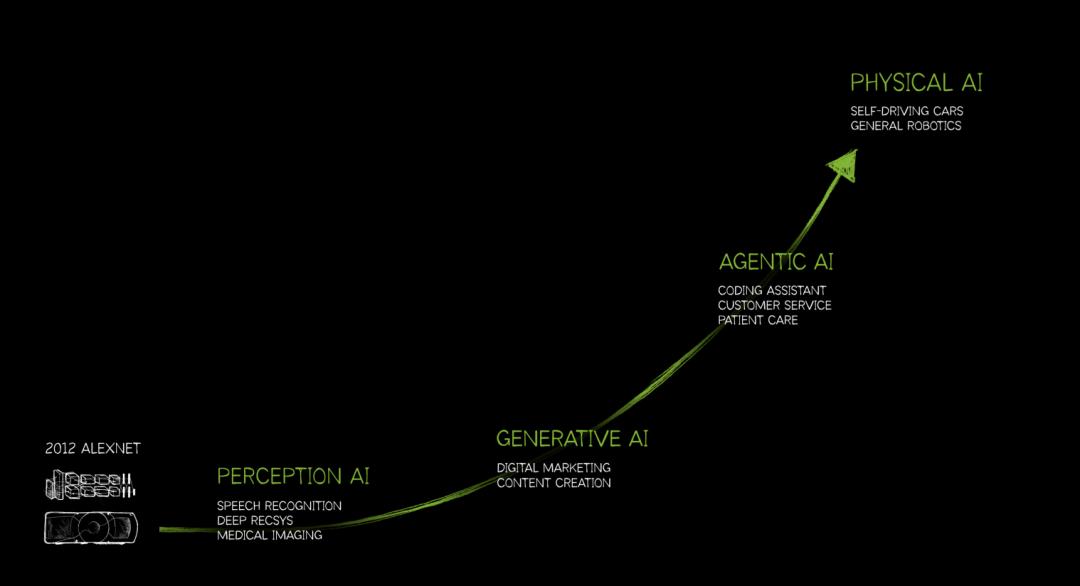
反驳视频生成模型的理由是这样的:
AI生成的视频很美,但如果你走进那个视频,试图拿起桌上的杯子,你的手会穿过去。
杯子没有重量,没有摩擦力,没有物理法则。
那不是世界,那是动画片。下一波浪潮,必须是懂物理的AI。
当时,很多人以为这只是老黄的营销话术,最终目的是为了推销昂贵的Omniverse平台和RTX显卡。
直到CES 2026,大家才明白老黄说的对。

刚刚,我们发现英伟达甩出了一篇新年第一篇论文:3D通才模型。

链接:https://research.nvidia.com/publication/2026-03_3d-generalist-vision-language-action-models-crafting-3d-worlds
如果说ChatGPT是AI学会了「说话」,Sora是AI学会了「做梦」,那么英伟达的这个新模型,就是让AI真正「睁眼看世界,动手造世界」。
这是图形学的胜利,这是「硅基生命」长出四肢的前夜。
老黄没有画饼——
物理AI的「ChatGPT时刻」,在这一刻,正式降临。

英伟达开年首篇论文,手搓赛博房之家
这篇论文由英伟达和斯坦福大学合作,正式发表在今年第十三届国际三维视觉会议上,标题相当拗口——
《3D Generalist:Vision-Language-Action Models for Crafting 3D Worlds》(3D通才:用于构建三维世界的视觉-语言-动作模型)。

2026年3月20日至23日,第十三届国际三维视觉会议2在加拿大不列颠哥伦比亚省温哥华的温哥华会议中心以线下形式举行
我们要读懂这次技术革命,首先要从这篇论文标题里,把那个最核心的单词揪出来。
请盯住这个词:Action(动作/行动)。
这是整个逻辑的起点。
在过去的三年里,无论是Midjourney画图,还是Runway生成视频,AI扮演的角色都是「观察者」和「梦想家」。
它看了一亿张猫的照片,然后根据概率,在屏幕上预测下一排像素应该是什么颜色,从而凑出一只猫的样子。
它不知道猫有骨骼,不知道猫毛有触感,它只是在「模仿视觉信号」。
但英伟达的VLA(Vision-Language-Action)模型,彻底颠覆了这个逻辑。
它不再是画家,而是「全能手」。
你只要输入一句话,3D-GENERALIST就能输出包含完整3D布局的房屋。
这些3D布局包括材料、固定装置(比如门和窗户)、3D资产以及照明配置。

背后的理念是,构建一个既详细又与文本描述相符的3D环境,应该被视为一个过程,需要依次做出决策。
因此,通过场景级和素材级的策略,他们不断改进和优化这些3D环境。
在提出的框架中,第一个重要的模块是全景环境生成。
如图2所示,这个模块能够根据文本描述初始化一个基础的3D房间模型,包括墙壁、地板以及固定装置,如门和窗户。
为了避免传统方法过于简化或不切实际的问题,他们首先利用全景扩散模型生成一个360°的图像作为指导,然后通过逆图形技术构建3D环境。
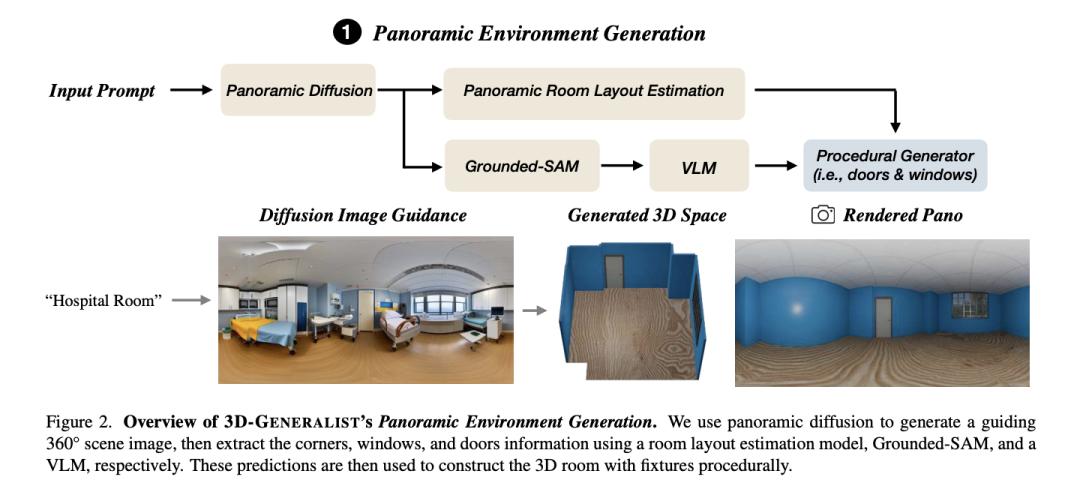
图2:3D-GENERALIST全景环境生成概述。全景扩散模型生成引导性360°场景图像,然后房间布局估计模型、Grounded-SAM和视觉语言模型提取角落、窗户和门的信息。这些预测随后被用于通过程序化方式构建带有构件的3D房间
这个过程包括以下几个步骤:
房间布局估算:利用全景图像和HorizonNet模型,推断出房间的基本结构,如墙壁、地板和天花板。
固定装置分割:使用Grounded SAM技术对窗户和门进行分割。
视觉-语言模型注释:通过GPT-4o这样的视觉-语言模型,分析每个分割区域,确定其类型(例如单扇门、双扇门、滑动门或折叠门)和材料(如门框、门体和门把手的材料)。
过程化生成:最后,根据3D位置的相应信息,房间、门和窗户被逐步构建出来。
3D-Generalist 使用扩散模型生成全景图像,并通过逆向图形(inverse graphics)流水线来创建3D环境的结构。
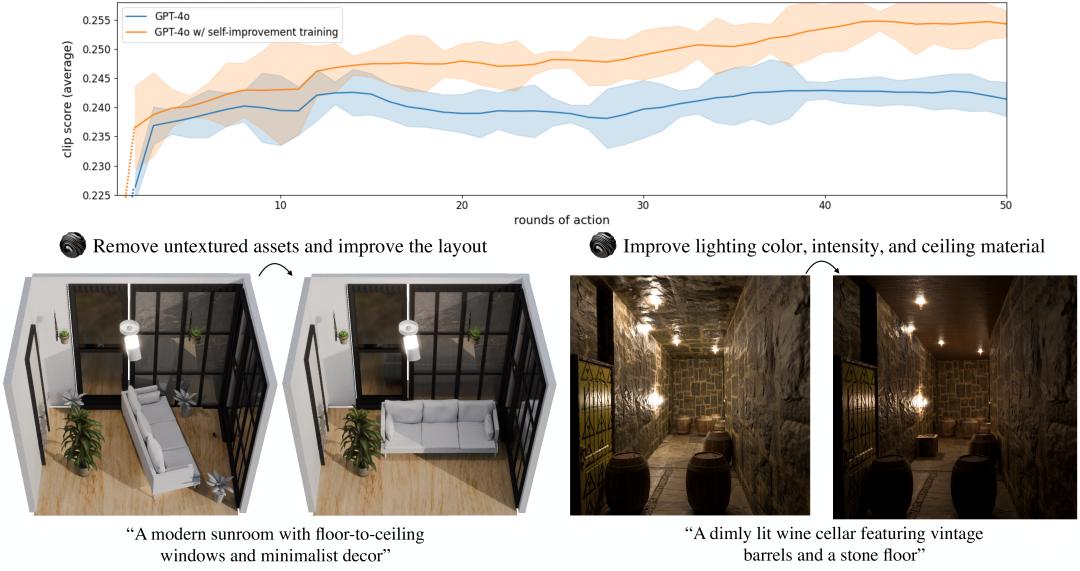
3D-Generalist采用视觉-语言-动作(VLA)模型来生成代码,用于构建与修改最终3D环境的各个方面(材质、光照、素材与布局)。
该VLA通过一个自我改进训练循环进行微调,以优化与提示词(prompt)的对齐效果。
3D-Generalist还使用了另一个VLA来处理多样化的小物体摆放任务,即使 3D素材是无标注(unlabeled)的也能完成。
微调后(After Finetuning),3D-Generalist涌现出自我纠错行为。
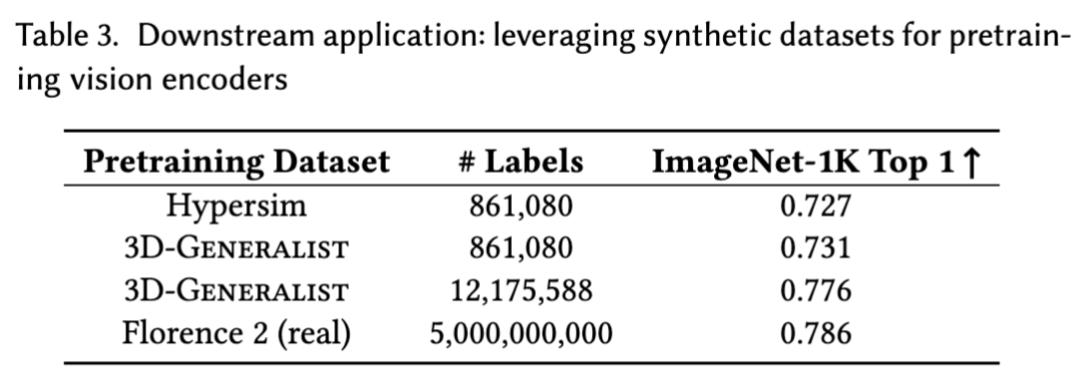
研究团队还使用Florence-2框架,在由3D-Generalist生成的3D环境渲染得到的合成数据上训练一个视觉基础模型。
结果表明:其效果接近使用规模大几个数量级的真实数据所能达到的效果。
物理AI的ChatGPT时刻,已开启?
如果你认为黄仁勋费尽心机搞这个,只是为了让你玩游戏更爽,或者让视觉特效更便宜,那你严重低估了英伟达的野心。
英伟达不只是买买游戏显卡,更致力于解决「智能」算力问题。
这篇论文的真正战略意图,其实藏在英伟达宏大的「具身智能」(Embodied AI)版图中。
老黄早已押注机器人,他认为那是一个数万亿美元的机遇:

这次无疑是英伟达「秀肌肉」。
请看这个逻辑链条:
我们想要全能的机器人(比如特斯拉Optimus,或英伟达Project GR00T)。
机器人需要学会像人一样处理复杂的物理世界(怎么拿鸡蛋不碎?怎么在湿滑地板上走路?)。
在真实世界里训练机器人太慢、太贵、且不可逆(你不能让机器人摔坏一万个鸡蛋,或者摔断一千次腿)。
解决方案: 把机器人扔进「虚拟世界」里训练。
但是,以前的虚拟世界(模拟器)不仅搭建很慢,而且不够真实。
如果模拟器里的物理规则和现实不一样,机器人学出来的本事就是花拳绣腿,一上真机就扑街。
现在,新模型「3D通才」补上了这一环。
有了这个技术,英伟达可以瞬间生成数百万个包含不同物理变量的「虚拟平行宇宙」。
场景A:地板刚拖过,很滑,光线昏暗。
场景B:地板铺了地毯,摩擦力大,强光照射。
场景C:地板上散落着乐高积木,障碍物复杂。
在这个无限生成的「3D物理世界」里,机器人大脑可以在一天之内经历人类几百年的训练时长。它在虚拟世界里摔倒一亿次,就是为了在现实世界里稳稳地迈出第一步。
在英伟达的Omniverse生态中,研究团队使用Omniverse Replicator实现大规模合成数据生成,并支持域随机化(domain randomization);而Isaac Lab提供可直接使用的具身载体(例如人形机器人),可在这些生成环境中进行机器人仿真。
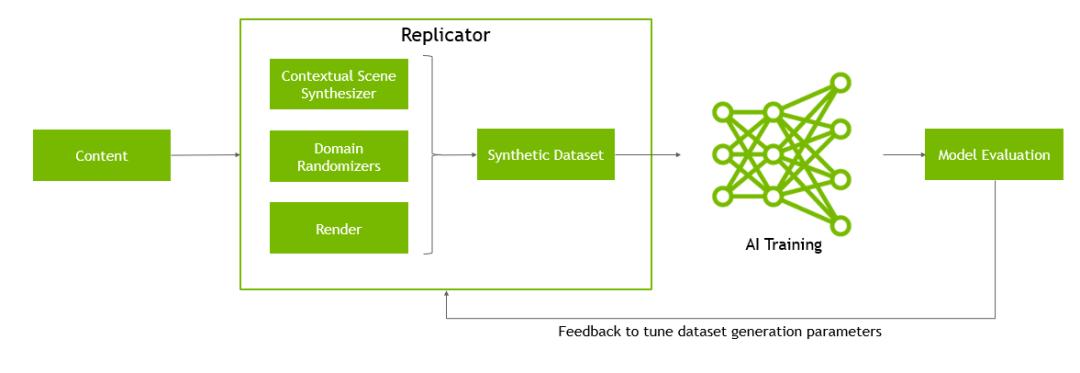

这才是「物理AI」的终极目标:打通Sim-to-Real(从模拟到现实)的最后一公里。
黄仁勋构建的不仅仅是一个生成的引擎,它是硅基生命诞生的子宫。
所有移动之物,终将自主
当AI不仅掌握了人类的语言(GPT),掌握了人类的视觉(Sora),现在又掌握了构建物理世界的法则(Physcial AI)时,虚拟与现实的界限,将不再是泾渭分明的。
我们在屏幕里创造的世界,将拥有和现实世界一样的重力、光影和因果律。
而我们在现实世界里的机器人,将拥有在数亿个虚拟世界里磨练出来的智慧。
在2024年的SIGGRAPH大会上,黄仁勋曾说:「Everything that moves will be autonomous.」(所有移动之物,终将自主。)

当时我们以为他在说机器人。
现在看来,他说的是整个物理世界。
作者介绍
Fan-Yun Sun

Fan-Yun Sun是斯坦福大学AI实验室(SAIL)的计算机科学博士生,隶属于Autonomous Agents Lab和斯坦福视觉与学习实验室(SVL)。
在读博期间,他也深度参与了英伟达研究院的工作,曾效力于学习与感知研究组、Metropolis深度学习(Omniverse)以及自动驾驶汽车研究组。
他的研究兴趣主要在于生成具身(3D)环境与数据,用于训练机器人和强化学习策略;致力于推动具身、多模态基础模型及其推理能力的发展。
Shengguang Wu

Shengguang Wu目前是斯坦福大学计算机科学系的博士生,师从Serena Yeung-Levy教授。
他在北京大学获得硕士学位,导师为Qi Su教授;此前,他也曾在Qwen团队担任研究实习生。
他的研究致力于赋予机器跨多模态的类人学习与推理能力,并推动现实应用的落地。
多模态Grounding与推理:利用视觉洞察来优化基于语言的推理,同时引入文本反馈来指导细粒度的视觉感知。
自我提升:让AI智能体能够从交互中学习并持续自我进化——主动适应新信息,并随着新任务的出现不断成长。
Jiajun Wu

吴佳俊是斯坦福大学计算机科学系助理教授,同时兼任心理学系助理教授。
在加入斯坦福之前,他曾在Google Research担任访问研究员,与Noah Snavely合作。
他本科毕业于清华大学交叉信息研究院「姚班」,师从屠卓文(Zhuowen Tu)教授。在清华期间,他曾连续三年保持年级第一,并荣获清华大学最高荣誉——特等奖学金以及「中国大学生年度人物」称号。
随后,他在麻省理工学院获得电气工程与计算机科学博士学位,导师是Bill Freeman和Josh Tenenbaum。
吴佳俊的团队致力于物理场景理解的研究——即构建能够「看」见世界、进行推理并与物理世界互动的机器,其代表性项目包括Galileo、MarrNet、4D Roses、Neuro-Symbolic Concept Learner以及Scene Language。
除了开发表征本身,团队还同步探索这些表征在各个领域的应用:
多模态感知,代表项目如ObjectFolder和RealImpact;
4D物理世界的视觉生成,代表项目如3D-GAN、pi-GAN、Point-Voxel Diffusion、SDEdit和WonderWorld;
基于物理概念接地的视觉推理,代表项目如NS-VQA、Shape Programs、CLEVRER和LEFT;
机器人学与具身智能,代表项目如RoboCook和BEHAVIOR。
Shangru Li

Shangru Li是英伟达高级系统软件工程师,长期从事智能视频分析(IVA)和Metropolis平台的相关工作。
他拥有宾夕法尼亚大学计算机图形学与游戏技术工程硕士学位,以及广东外语外贸大学计算机软件工程学士学位。
其他华人作者还有:
Haoming Zou (Stanford University)
Yu-Hsin Chou (Stanford University)
Xunlei Wu (NVIDIA)
参考资料:
https://research.nvidia.com/publication/2026-03_3d-generalist-vision-language-action-models-crafting-3d-worlds
