

已经上岸的中国大模型双雄智谱(02513.HK)与MiniMax(00100.HK)迎来了一个相似的关键性时刻:3000亿市值的高估值、超预期的营收高增。
今年3月,两家公司均已公布上市后的首份年度财报,向投资者展示了各自的「首秀」成绩单,除了三位数的营收增速外,双方又默契地各自向资本市场提出了一个公式,
智谱给出的公式是:AGI商业价值=智能上界×Token消耗规模;MiniMax的公式是:“平台价值=智能密度×Token吞吐量。”

给公式的原因既是为了明确自身的差异性,也是为了给自己定价。
智谱和MiniMax的公式有共性,它们都认同模型的商业价值衡量标准来自Token的消耗规模;但也有明显的差异,智谱仍是认为自己是面向B端的大模型公司,但MiniMax更看重自己C端的平台化能力。
两个公式,是两种战略和命运的分化,而两家公司上市后的首份年报里,也写满了中国大模型公司的苦与甜。
1、营收狂飙背后,业务结构都在变化
先看两家公司提到的Token消耗规模,这直接和收入的增长挂钩。
过去一年,智谱全年营收约7.2亿元人民币,同比增长132%;MiniMax营收7904万美元(约5.6亿元人民币),同比增长159%。
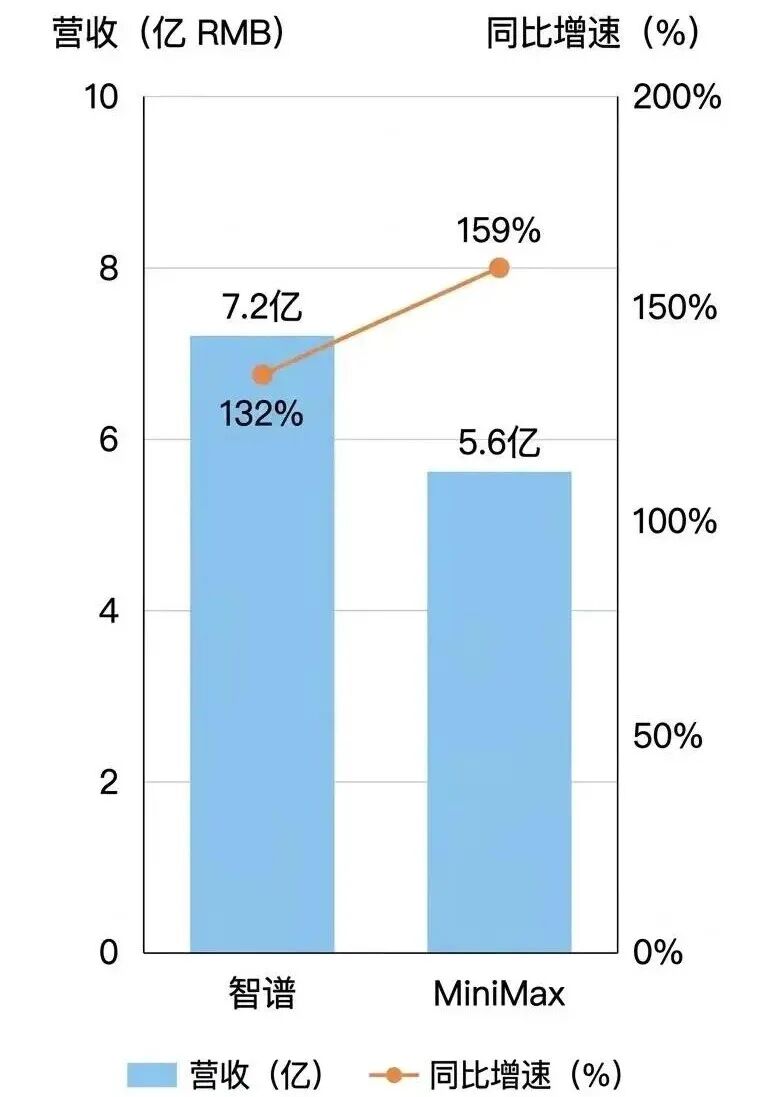
从收入规模看,智谱是MiniMax的1.3倍,但从收入增速来看,MiniMax明显优于智谱。
深入来看,两家公司的营收结构也在悄然发生变化。
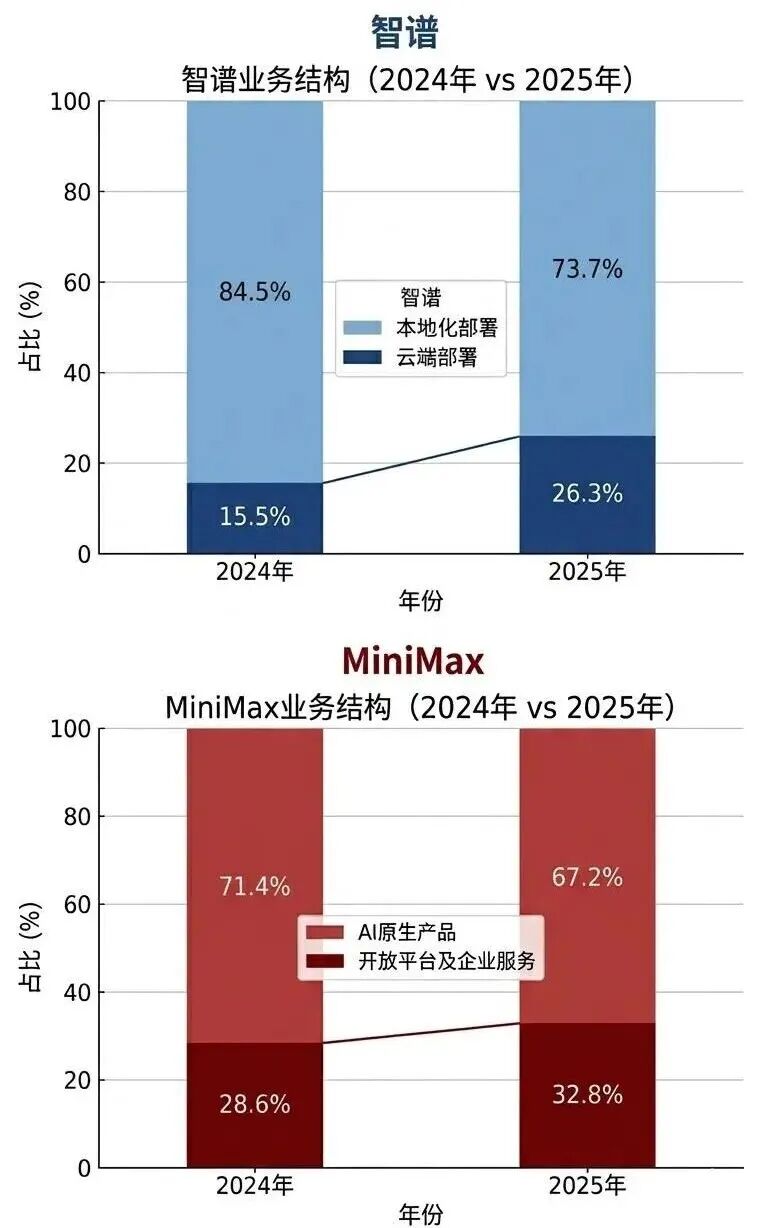
智谱呈现出「本地化部署快速下降、云端部署迅速占比提升」的趋势。
2024年,智谱的云端部署收入仅占15.5%,本地化部署贡献超八成营收。但一年过后,云端部署业务收入已暴增至1.9亿元,占总收入比例一举跃升至26.3%。
云端部署主要为API和开放平台,和本地部署业务的重交付、长回款不同,云端部署标准化、轻量化且高商业化效率,因此收入增长短期更可见。
MiniMax的收入增长主要靠C端的AI原生产品,包括海螺AI、Talkie及星野等,超七成营收也都在国际市场。但过去一年,开放平台及其他基于AI的企业服务收入占比从28.6%上升到32.8%,同比增长197.8%。
换言之,同样依靠API的轻资产,MiniMax在to B端的收入也在迅速起量。
两家公司收入的激增,要感谢OpenClaw等智能体的爆发。MiniMax就提到,OpenClaw在去年11月份推出后,其API接口收入占比已接近41%,增速同比接近300%。

除了外部Agent的推动,MiniMax和智谱也确实是大模型「卷王」,毕竟API的规模增长,依靠模型的质价比。
MiniMax用108天完成从M2到M2.5的三代演进,智谱在今年2月推出了备受好评的GLM-5。「硅基研究室」也观察到,在「养虾」热潮中,MiniMax和智谱也是快速推出Coding Plan、适配多平台的大模型企业之一。
尽管有着不同的产品哲学和增长路径,但两家企业的任务殊途同归,就是用尽一切力气扩大Token消耗规模。
2、不同的变量,相似的挑战
从两家企业给出的公式来看,「智能密度」和「智能上界」是估值和增长的关键差异点。
智谱口中的「智能上界」更强调的是模型能力的代际领先,因为模型能力直接决定了API的定价权。
这背后有两个驱动因素——
一是,随着模型能力走向真实交付,包括智能体编码、长时程工作流等能力将成为模型厂商竞争关键,用户也会以效果和任务付费,而非考虑token单价。
二是,硬件、算法的改善,拉动推理单位成本的持续下降,这也会给无法快速迭代模型能力的厂商带来定价压力。
摩根大通就指出,留在能力前沿的模型有望同时实现量价双升,未能持续改善的模型则更可能在使用量增长的同时面临价格下滑,利润率前景不确定。
MiniMax强调的「智能密度」则是一种效率指标。
在我们看来MiniMax更像是在说单位Token内的有效智能价值。效率也是创始人闫俊杰经常提到的关键词,他曾表示,2025年寻求训练的效率,今年将会转向追求更高的研发效率和模型迭代效率。
因此,同样是专注模型迭代,MiniMax看重的是模型的效率和组织的效率,其和智谱的差异化在于:第一,MiniMax追求全模态,把语言、视频、语音、音乐等主要模态都尽量跑通,追求端到端的效率;第二,模型能力和产品迭代同时进行,瞄准商业化落地。
除此以外,MiniMax的组织效率也更高,人均创收能力更强。我们计算了两家公司去年的人效比,MiniMax是智谱的2倍,以不到智谱一半的人手实现相近收入,人效更高。
尽管「智能密度」和「智能上界」是不同的变量,但两家企业的挑战是类似的。
首先是账面的亏损。
2025年,智谱经调整净亏损约31.8亿元,较2024年扩大29.1%,MiniMax经调整净亏损约2.5亿美元(约17.2亿元人民币),同比仅小幅增长2.71%,两家公司平均每天就亏了超1300万。
虽然智谱和MiniMax部分业务的毛利水平有所优化,规模效应初步显现,但距离盈亏平衡仍有相当大的距离。
其次是算力瓶颈。
智谱CEO张鹏此前提到:“大模型未来12个月面临的最大问题可能是算力。”

和chatbot不同,使用Agent完成一次任务背后触发的是几十上百次的模型调用,复杂任务甚至对应几万到百万Token,被人们吐槽「Token黑洞」的小龙虾已经印证了这一点。
更关键的是,智谱和MiniMax并不是自购芯片或自建数据中心,它们的算力支出实际都流向了云厂商,本质上属于算力下游的他们也会面临算力的「卡脖子」。
换言之,随着OpenClaw等应用驱动的Token消耗进入指数级增长,两家公司都面临着「有需求、无算力」的窘境。
3、两个公式,再看中国大模型的未来
而两家公司给出的两个公式,折射出中国大模型行业的新趋势。
第一,模型公司的研发会转向智能体思维。
闫俊杰认为强调工具级能力的L3级智能体已经到来,迈向L4-L5级智能则是同事和组织级能力,他提到一个观察,公司内部正在经历一个明显转变,员工正从「教Agent如何工作」逐步转向「观察Agent如何工作」。
这也意味着,大模型公司的模型研发会从让模型「多想一会儿、推理链更长」变成「模型以更有效的方式来思考」。
从阿里离职的林俊旸也提到了类似的观察,模型架构和训练数据仍重要,但环境设计、rollout基础设施、评估器的稳健程度、多个Agent的协调进入了核心圈。
第二,单用户token消耗量的指数级提升,对大模型公司推理算力的计算系统提出了新要求。
对推理算力和推理效率的优化,不只是推理算力「够不够」的问题,更在于能否扛住高并发高吞吐、实现持续降本以及和国产芯片做适配。
智谱提到,公司正在加大国产芯片的「Day 0」适配与软硬一体化调优投入。MiniMax也公布了推理效率的优化成果。数据显示,截至2026年2月,M2.5系列每百万Token推理算力成本较2025年12月下降逾50%,Hailuo视频生成模型推理延迟降低逾30%。
第三,模型能力竞争从卷速度、卷价格转向了卷价值,未来谁能够在高价值场景中掌握API的定价权是关键。
智谱高管在业绩交流会上也提到一个观察:“随着Agent的演进,Token也会分层,低复杂度、标准化的token走向低价甚至免费,高复杂度、高可靠性的高质量token具备持续定价权。”
对API定价权的关注背后是大模型公司智能稀缺性的体现,这也是为什么智谱反复向资本市场强调API涨价口,仍供不应求的原因所在。
这也预示了,中国大模型赛道将走向「头部分化」,新的淘汰赛正在加速。
截至发稿前,智谱市值达3092亿港元,MiniMax市值超2915亿港元,它们已代表了两种不同的进化路径——智谱的B端模型能力路径、MiniMax的C端「产品+效率」模式,也为AI创业提供了两个可参考的样本。
但对二级市场而言,大模型双雄当下的高估值仍受到市场的审慎目光,未来的时间内它们依旧需要证明中国AI企业的多元创新能力和创收实力,除了ARR、Token消耗增速、高价值业务场景、营收增速等基本指标,还有给到市场更多的情绪价值,争取更多的支持。
这也是为什么智谱在业绩电话会上花了大量篇幅去对标Anthropic,讲述Token架构力的故事。
在中国大模型公司发布业绩的同时,大洋彼岸外他们的对标对象也开启了新一轮动作—OpenAI完成了新一轮融资,个人投资人也进入了名单里。
Anthropic以意外方式将编程工具Claude Code的万行源码暴露在人们面前。
理解中国大模型双雄两个公式背后的逻辑,或许比记住公式本身更加重要,毕竟,在这个快速变化的时代,唯一不变的,是变化本身。
