

DeepSeek的Harness团队在北京海淀区融科资讯中心,十年前我曾在那里工作。这不是想往脸上贴金,而是很遗憾,错过了见证历史的一刻。
6月16日,据媒体报道,DeepSeek完成了成立以来的首轮外部融资,募集资金超过500亿元人民币,投后估值突破500亿美元。创始人梁文锋个人出资200亿元,为最大单一出资方;腾讯出资100亿元,宁德时代体系出资约50亿元,京东、网易及IDG资本各出资30亿元。
这是中国AI行业迄今规模最大的单轮融资。
那么,拿到巨额融资的DeepSeek,会把钱投向哪个方向?
6月15日,从论坛流出的一则信息可能让我们可以管中窥豹。据一位参与测试的用户称,DeepSeek V4.1在网页端启动灰度测试,他说V4.1 Flash的代码能力实现了“天差地别”的跨越式进步,知识截止日期也从2025年5月跃升至2026年1月,部分用户甚至测出了2026年5月的截止日期。
很可能AI coding就是DeepSeek即将发力的方向。
其实,5月,DeepSeek的一则招聘启事也透露了这点,那则Agent Harness研发工程师的招聘启事里,写了一行简洁的公式:Model + Harness = Agent。岗位描述进一步解释道,“把前沿模型能力,转化为领先的Agent产品。Harness+除模型本身以外的所有工作”。
AI coding+Agent,看来,DeepSeek接下来的目标是想对标Anthropic旗下的Claude Code。DeepSeek做coding,因为这个领域能用最严格的标准来测试和锻造模型的推理能力,不仅是目前唯一被验证的、能形成商业闭环的场景,更是AI生产力的基础设施。
01
DeepSeek没兴趣在C端和豆包、千问、元宝争夺用户。从这轮融资的资金用途、产品布局、人才引进以及市场验证来看,DeepSeek的战略意图很清晰:服务好开发者和企业,把模型能力转化为生产力工具,成为AI时代的“基础设施”提供商。
虽然DeepSeek没有公开资金分配比例,但从其战略意图和行业趋势,可以反推可能的分配比例:
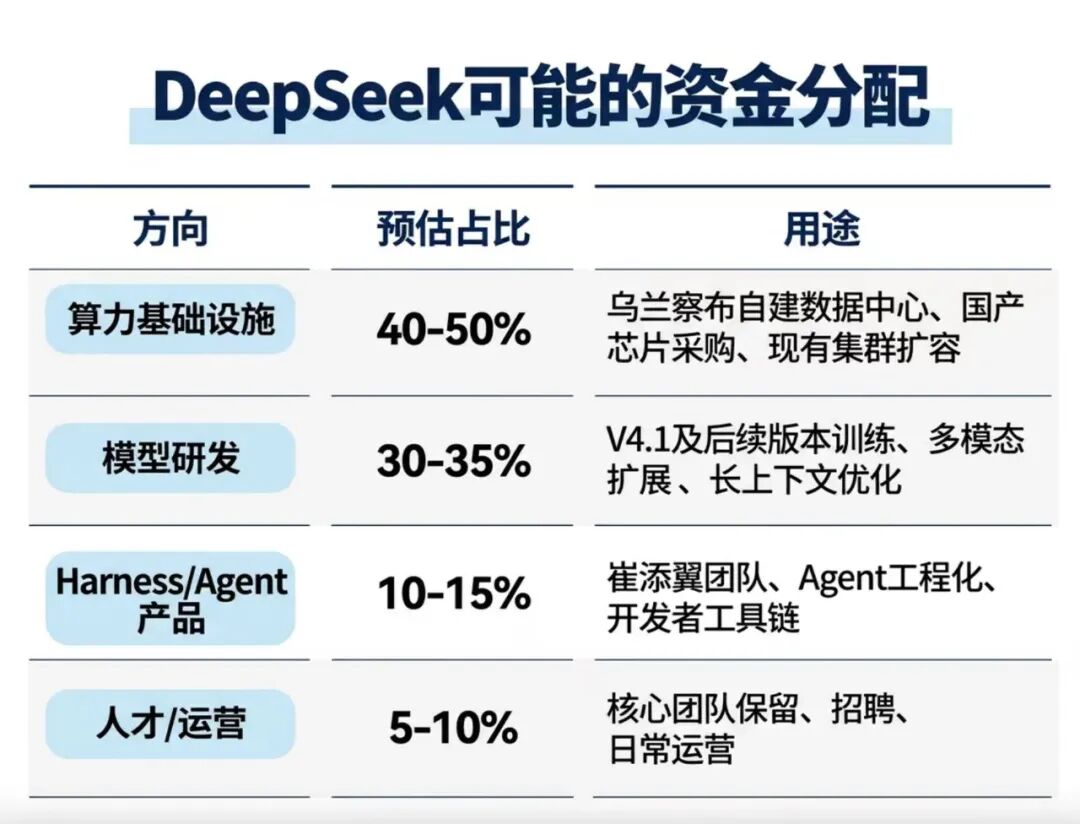
500亿的大头大概率会砸在算力上,毕竟从长远来看,DeepSeek始终处在算力边际紧缺的状态,无论是要训练出新一代模型,还是要满足用户调用量的增长。
前段时间,DeepSeek在内蒙古乌兰察布招聘智算中心人员,岗位有高级运维工程师、高级交付经理,月薪开到15K到30K,还配14薪,还设立“IDC设计规划工程师”岗位,规划MW到GW级的超大规模智算中心。这说明,DeepSeek正从租用机房转向大规模自建数据中心。
我们了解到,除了自有算力,早在2025年,浙江很多空置的算力中心都给DeepSeek调用。即便有外部算力供给,算力依旧是以及会是DeepSeek长期要面对的难题,近期其“专家模式”取消了联网搜索功能,并且限制生成次数,就从侧面说明了这点。
算力是Coding基础设施的物理底座。如果V4.1的性能提升,调用量增加,以现有算力更难承受。没有算力,V4.1再强也只能限流,没有算力,Harness再好用也跑不起来。
可以相比较的是在coding领域最强的Anthropic,它采取“多云绑定+专属集群”的激进策略,已构建覆盖GPU、TPU及自研芯片的多元供应网络,2025年底可用算力约1.4吉瓦,预计2026年底将快速提升至7-8吉瓦区间。但仅2026年第一季度其收入与使用量按年化计算就增长80倍,远超原有基础设施承载能力,导致服务曾出现限流与性能波动。
Anthropic CEO达里奥·阿莫迪表示算力需求呈指数级爆发,公司正全力建设以匹配这一“疯狂”增速,目标是在未来几年内实现吉瓦级容量的持续释放。
AI Infra(基础设施)是一项重资产、长周期的投入,DeepSeek还在高速发展,理论上,它完全可以租用更多算力,为什么要自己费力为处理海量、复杂的B端AI工作负载提供稳定、低成本的算力底座呢?
因为DeepSeek的技术路线,决定了它必须拥有Infra的绝对控制权,必须在Infra层就做优化。
为了尽量压榨算力,DeepSeek做 FP8训练,需要写通信库、调精度补偿策略、改NCCL,英伟达原生的通信库不支持这种级别的自定义;DeepSeek自己重新设计KV Cache的存储和调度,因为标准推理引擎(vLLM、TensorRT-LLM)的架构假设和它要的不一样;DeepSeek要设计MoE负载均衡,自己写路由算法,让专家分布在特定的节点拓扑上,减少跨机通信,而不能简单用云厂商的Kubernetes自动扩缩容。等等。
这些都需要在“算法-芯片-网络-框架”的每一层做定制优化,云厂商的标准化服务满足不了。Anthropic能继续堆参数、超大规模路线,是因为它有亚马逊云和Google Cloud的可“无限扩容”算力支持,用不着在Infra层面做极致优化。
DeepSeek没有这个条件,所以只能自己做地基,但这些努力也正是DeepSeek的竞争力来源。
这些优化不是孤立的,而是乘法关系。从公开的技术架构差异和行业成本模型,架构优化× 精度优化× Infra优化× 推理优化叠加,使得DeepSeek的单位算力成本比Anthropic的低得多。
02
算力是地基。地基之上,DeepSeek另两个大投入方向是模型层和执行层。
6月15日那则V4.1灰度测试的帖子,透露的是DeepSeek在coding领域的进展。据参与测试的用户称,V4.1 Flash的代码能力实现了“天差地别”的跨越式进步。但我们没能参与灰度测试,目前并不了解具体实际情况。
DeepSeek V4曾以1.6T总参数、1M上下文窗口,在架构效率和成本结构上实现了全面突破。但V4的Coding能力与业界顶尖水平仍有差距,这也是社区讨论最多的短板。V4.1的核心任务,正是开始补齐这块短板。
从序列号来看,V4.1是V4的增量版本,这意味着V4.1的核心投入在后训练阶段(Post-Training),而非预训练(Pre-training),后训练成本通常只有预训练的1/10到1/5。
DeepSeek朝生产力演进的方向已经很明确的,而这正是国内大模型企业与国际最高水平对比最大也是最紧迫的短板。
如果把AI模型比作大脑,Agent/Harness这个执行层就是它的手脚和神经系统。没有执行层,大脑只能思考;有了执行层,大脑才能行动。过去一年,行业已经证明了一个事实:模型能写代码,不等于能持续完成一个工程任务。真正改变开发者工作方式的,是Claude Code、Codex,一个能够进入终端、理解项目、读写文件、运行命令、修复错误、管理Git、调用工具的工程智能体。
Coding是Harness的最佳载体,因为代码本身就是可执行的意图,一行代码既是对问题的描述,也是对解决方案的精确指令。
Anthropic是最早把“模型写代码”升级为“模型做工程”的公司。2024年推出的Claude Code(以及此前的Claude Dev、Artifacts等功能),不是简单的代码补全工具,而是一个完整的终端工程环境。Claude Code的火爆证明了一件事:AI Coding的竞争,正在从模型能力竞争,转向开发者工作流入口竞争。
模型是大脑,但大脑不能自己打字,你需要一套系统,把模型的意图转化为行动。那就是Harness。
Anthropic的AI coding端到端工程闭环的体验,是模型能力+Harness工程的双重积累。 Anthropic比竞争对手早6-12个月跑通了这个闭环,形成了开发者习惯壁垒。当DeepSeek还在做模型层时,Anthropic已经在做工作流层了。
这种领先不只是无限算力加持下超大规模模型的能力输出,也是工程打磨的结果,这需要大量产品工程师、开发者体验设计师、DevOps专家的反复迭代。
所以,DeepSeek在推进V4.1乃至V5的研发的同时,也在补足Agent/Harness能力。5月那则招聘启事里的公式,Model + Harness = Agent,说的就是这个。
据媒体报道,DeepSeek Harness团队的负责人是崔添翼,一位在Jane Street干了9年、后来联创量化基金TSY Capital的交易系统专家。2026年2月,他离开TSY Capital加入DeepSeek。DeepSeek找他来,正是为了搭建Harness。
DeepSeek找了一个做量化交易系统的人来搭建Harness。这个选择背后的逻辑,比“同行相惜”要深得多。
一个逻辑合理的解释是,量化交易和AI Agent的底层逻辑是一样的:光有聪明的策略不赚钱,真正把策略变成钱的,是执行系统。光有强模型也不够,真正把模型变成生产力的,是上下文管理、工具调用、终端执行、测试反馈、权限控制、失败回滚。这些除模型本身以外的所有工作,都属于Harness的范畴,也就是“执行”。
V4.1解决的是“能不能写对代码”,Harness解决的是“写完后能不能跑通、报错后能不能自修、项目大了能不能协作”。前者是模型能力,后者是工程能力。只有两者结合,DeepSeek才有机会建立与Claude Code同级别的端到端工程智能。
这种挑战巨头的尝试,对工程师有很大的吸引力。目前,崔添翼在社交媒体上发布的招聘帖子,已经引来众多业界人士的投递。
03
Coding之所以成为必争之地,是因为它是目前唯一可验证、可量化、可闭环的AI生产力。
判断一个AI能力达不达到生产力水平,有一个简单的标准:它的输出能不能在不依赖人类主观判断的情况下,被验证对错?
多模态模型生成一张图,好不好看?需要人看。通用对话模型回答一个问题,对不对?需要人判断。这些能力的验证成本极高,且标准不统一,企业很难量化ROI。
但Coding的输出是一段程序,计算机可以直接执行并给出pass/fail。写对了就运行,写错了就报错。这种自动可验证性使得Coding成为目前唯一一种ROI可以被精确计算的AI能力,企业能算出这个模型替代了多少工程师工时、产出了多少可运行代码、减少了多少bug。
2026年的benchmark竞争格局印证了这一点。SWE-bench Verified(让模型解决真实GitHub issue的测试)已经成为“single most-cited coding benchmark”和“most load-bearing single benchmark for real-world developer workflows”。根据第三方benchmark聚合平台llm-stats.com的数据,当前前沿模型在这个测试上的竞争进入了白热化:Claude Opus 4.5达到80.9%,Opus 4.6为80.8%,Gemini 3.1 Pro为80.6%,GPT-5.2为80.0%,差距仅在0.1到0.9个百分点之间。
但在SWE-bench Verified这样的真实任务上,0.9%的差距意味着:一个模型能独立解决某个复杂issue并上线运行,而另一个模型会在最后一步卡住。这不是差不多,而是能跑通和跑不通的区别。
而6月12日Anthropic被禁事件,进一步确认了Coding的基础设施地位。Anthropic最强大的模型Claude Fable 5和Mythos 5被美国政府纳入出口管制,当天全球停服。这是美国首次将商业AI模型与先进半导体同等对待,纳入出口管制清单。Fable 5的定价是input $10/M、output $50/M,这不是软件工具的定价,而是基础设施的定价。
是的,AI coding已经是AI时代的生产力基础设施,有没有是两个时代的分野:AI生产力时代和前AI生产力时代。这反向验证了DeepSeek朝AI coding演进的意义:Coding基础设施不能被垄断,必须平权化。
DeepSeek-V4-Flash缓存命中输入价格仅为0.2元/百万tokens,约为Fable 5的1/138。但实际操作中,由于能力的欠缺,总的token成本并不一定比Fable 5低,更重要的是为生产力付费有马太效应:最好用的会收获绝大多数用户,形成正反馈飞轮,而能力稍显欠缺的,可能就成Other。
但如果我们把AI coding看作是生产力基础设施,那么当Coding基础设施的边际成本不断降低,全球开发者也才能真正用上顶尖的Coding能力,释放巨大生产力。所以,以此为维度,DeepSeek的低价路线,本质上是把AI生产力从奢侈品变成日用品。
据参与融资的投资人转述,梁文锋对所有投资人的最大要求是“不要挖DeepSeek的人”。不是因为核心团队流失率高,事实上核心团队很稳定,离职者也不是做Coding的,而是当一个人坚信自己在做一件很重要的事情时,是不希望别人来挖角打扰的。
目前,Anthropic的Coding领先是算法+算力+工程化+时间差的红利,马斯克认为最早到明年Q1,中国AI团队就能造出Mythos 5量级的模型,但智谱的唐杰认为会更快。谁对谁错,由时间来证明。
但让AI成为像水电一样的基础设施,像TCP/IP、像Linux、像电网,成为准公共品(Quasi-Public Good),会是AI生产力释放的关键。DeepSeek拿着500亿,赌的就是Coding真正成为基础设施,人人可用。
DeepSeek如果能在coding上建立“低成本+高性能+完整工具链”的优势,它实际上是在把AI从消费叙事切换到生产叙事。这不仅对DeepSeek自己重要,对中国整个AI产业都很关键。
十年前,我在融科资讯中心工作时,那群楼里还没有一家AI公司,现在,DeepSeek的Harness团队正在那里面试产品经理。从乌兰察布的智算中心,到V4.1的蓄势待发,DeepSeek正在推进它的计划。
遗憾的是,我没能力参与其中,只能记下这些观察。让时间去验证它的对错。
