

2026年,国产GPU行业正处在一个微妙的十字路口。一方面,算力的野蛮生长,企业规模扩张带来了阶段性行业繁荣,政策扶持与资本追逐催生了前所未有的上市潮。另一方面,行业内部却弥漫着一种隐忧——堆砌纸面算力、回避真实场景落地的浮躁之风愈演愈烈。
推理场景平均利用率不足20%,训练场景平均利用率仅40%,理论算力持续飙升,实际场景效率却大打折扣。这种粗放式发展直接导致能效比例失衡、算力资源严重浪费,国产GPU陷入效率困局。
如何衡量一款国产GPU的价值?在1月26日举办的天数智芯合作伙伴大会上,这家全栈自研GPGPU七年,且刚刚实现港股IPO的企业试图给出自己的答案。在展现出技术创新、产品布局与生态建设上全栈实力的同时,天数智芯更多地通过千卡集群稳定运行超1000天、瑞幸咖啡数千门店部署、金融医疗等行业应用等商业案例,为国产GPU行业上了一堂生动的“落地课”。
当前,市场对GPU的关注从纸面算力快速转向应用效果,“好用易用”、“注重落地”正成为国产GPU应有的底色。
大芯片“三重门”
过去几年,以国产GPU为代表的大芯片赛道涌入大量玩家并迎来资本狂欢。据不完全统计,从初创团队到上市公司,国内宣称具备GPU研发能力的企业已超过20家,相关融资规模数百亿元。
然而,热潮涌动的背后,一些乱象也随之而生,主要体现在:
算力“纸面化”:一些厂商公布的TOPS(每秒万亿次操作)指标,往往基于稀疏计算或特定算子优化,这种针对实验室、特定场景和算法的定制指标,看似“性感”实则“骨感”,在真实大模型推理场景中利用率不足20%,与用户实际体验严重脱节。
参数“黑箱化”:多数厂商回避能效比、互联效率等硬指标,只谈 “对标旗舰”,却拿不出大模型训练的完整验证数据。口头强调自研,实则是购买第三方IP的“马甲”。
生态“口号化”:号称“兼容CUDA/PyTorch”等主流框架,但迁移成本居高不下,企业试用后因适配困难放弃。缺少足够的落地应用沉淀,产品只停留在PPT和数据参数。
一位国内系统大厂的工程师告诉集微网,他曾接待过国内知名GPU大厂的业务人员,其提供的产品,虽然算力够高性能强悍,但功耗却大得吓人。
“这样的产品完全忽视了实际场景中的能耗和成本考虑。我不知道会用在何处,是如何设计出来的。”该人士无奈地表示。
这种“重参数、轻落地”的倾向,正在透支行业信任,也让国产GPU难以叩开客户和行业的需求之门。
在过去几年GPU行业的喧嚣之中,天数智芯是十分低调的存在。这场发布会上,天数智芯也没有执着于参数的展示,而是用实实在在的商业合作案例和交付数据来展现成绩。这种“反套路”操作,恰恰扣中了行业最脆弱的命门——国产算力不仅“可用”,更能“好用”,“落地能力”才是国产GPU的发展关键。
作为国内成立最早,研发和量产落地最早的通用GPU厂商之一,凭借在行业领域的率先深耕,天数智芯在解决客户需求和场景痛点方面积累起大量实践经验。

面对国产GPU行业的“效率”困局,天数智芯给出的答案是——“回归计算本质”,算力价值不在峰值数字,而在于高效率、可预期与可持续。
在高效率方面,通过利用超高密度多核架构设计、打造并行任务处理模块、研发定制化量化算法等方式提升计算效率和性能表现,为客户创造最优TCO(总体拥有成本),从容应对复杂应用场景。
在可预期方面,借助精准仿真模拟系统,让客户在部署前即可预判性能表现。比如,可提前测算128卡、256卡集群的性能,拆解算子性能、PCA参数等核心指标,让客户清晰了解成本与收益,实现“所见即所得”。
在可持续方面,通过系统架构设计,实现对于主流CNN、RNN到当下火热的Transformer,再到未来未知算法的支持,无缝适配从传统算法到未来未知算法的演进,确保长期使用价值。
上述三个方面,就是天数智芯提出的“高质量算力”的核心内容,实际上是解决了客户对于国产GPU的核心顾虑和由此产生的递进式疑问:好不好用,现在和将来能不能用?这也是国产GPU落地的关键所在。
由此,天数智芯构建起差异化的产品竞争优势,即具有更强的适配性,无论算法如何迭代,基于通用计算本质,都能稳定发挥性能,也具备更好的成本、迁移性和兼容性。同时,所有数据与客户价值均经过实际应用验证和行业打磨,具有更高的产品成熟度。
硬核实力答卷
在以“高质量算力”为核心理念的指导下,天数智芯的这场大会,通过技术、产品、商业化的全维度突破,向行业与合作伙伴交出了一份扎实答卷。整体看来,呈现出如下几个亮点。

一是明确了未来三年的四代架构演进路线图,从2025年-2027年,天数智芯的天数天枢、天数天璇、天数天玑、天数天权架构,将实现对标和超越NVIDIA的Hopper、Blackwell、Rubin架构。
两三年前,可能没人相信中国企业能在GPU架构上接近甚至超越国际头部企业,但国内GPU厂商用行动证明,通过持续努力,这一目标已不再遥不可及。明确的架构演进路线和分阶段对标超越行业标杆,既是研发实力的体现,也给客户、投资者和行业带来清晰预期和信心。
在技术创新方面,天数智芯从架构核心IP到编译器、驱动全自研,是国内首家补全GPU全栈设计能力的企业,规避“卡脖子”风险,匹配国产GPU自主化的核心诉求。同时,聚焦通用GPU赛道(覆盖AI训练/推理、高性能计算、图形渲染),区别于部分友商单一场景定位,可适配不同行业的多元化算力需求,这一布局让其在科研、工业等非纯AI场景中更具竞争力。
二是四箭齐发,推出边端领域的 “彤央” 系列四款新品(TY1000/TY1100/TY1100_NX/TY1200)。

四款产品标称算力均为实测稠密算力,覆盖100T到300T范围,性能也能对标并超越行业主流产品。比如,在计算机视觉、自然语言处理、DeepSeek 32B大语言模型、具身智能VLA模型及世界模型等多个场景的实测中,彤央TY1000的性能全面优于英伟达AGX Orin。目前天数智芯的边端产品已在机器人智能、车路协同、智慧零售、智慧农业、AI-RAN等领域形成具体落地案例。
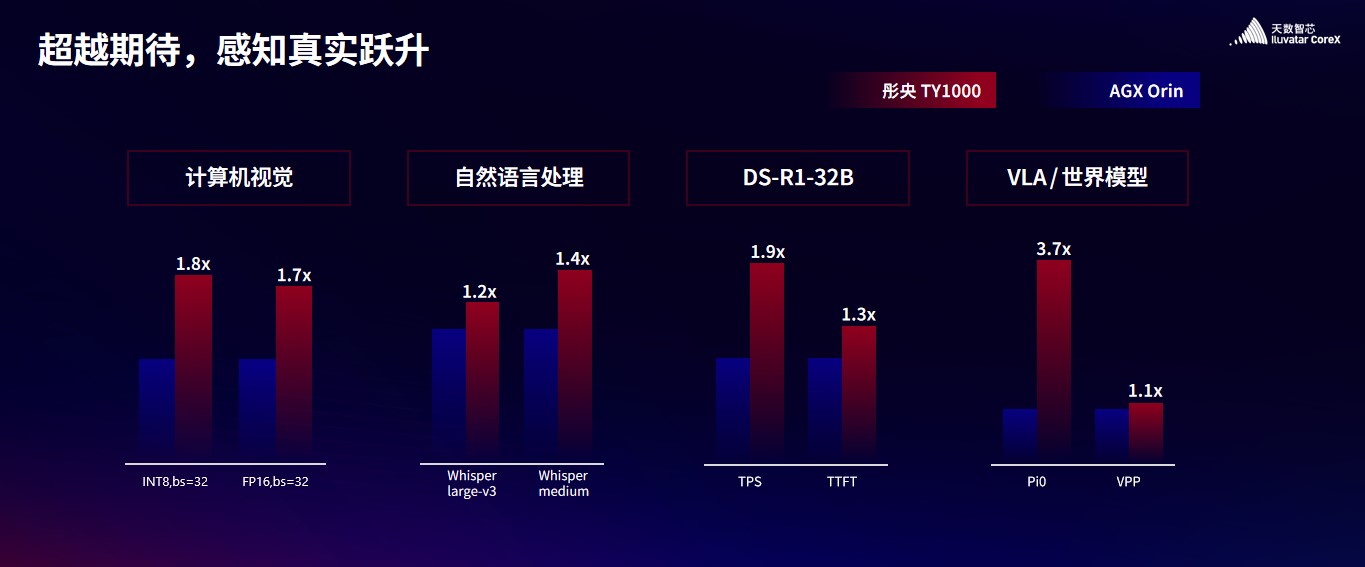
边端产品的推出,标志着天数智芯完成“云+边+端”全场景算力布局,成为目前唯一实现云边端全链路生态统一且全面兼容主流生态体系的国内头部GPU厂商。
这种全栈式布局构筑起天数智芯产品侧差异化的竞争壁垒。满足行业“协同算力”的刚需,解决单一场景的需求痛点。形成 “训练-推理-控制” 闭环,可解决客户“多厂商选型、跨平台适配”的痛点。

例如,瑞幸咖啡通过其 “云端调度+门店边端监测” 方案,实现数千家门店的数字化管控和数据分析,无需对接多个算力供应商,为门店运营大幅降本增效。
三是天数智芯首次公开了公司产品和解决方案在互联网、金融、医疗、科研等领域规模化落地成果,以及在具身、工业、商业、交通智能等领域的标杆案例。

技术领先最终需要通过商业验证。天数智芯招股书显示,2022-2024年营收复合增长率达68.8%,出货量从7.8千片增至2024年的16.8千片,三年内翻倍增长,2025年上半年的15.7千片,累计交付超5.2万片GPU,服务客户超300家,完成1000余次行业部署。
这些数字背后,是深入千行百业的场景深耕:
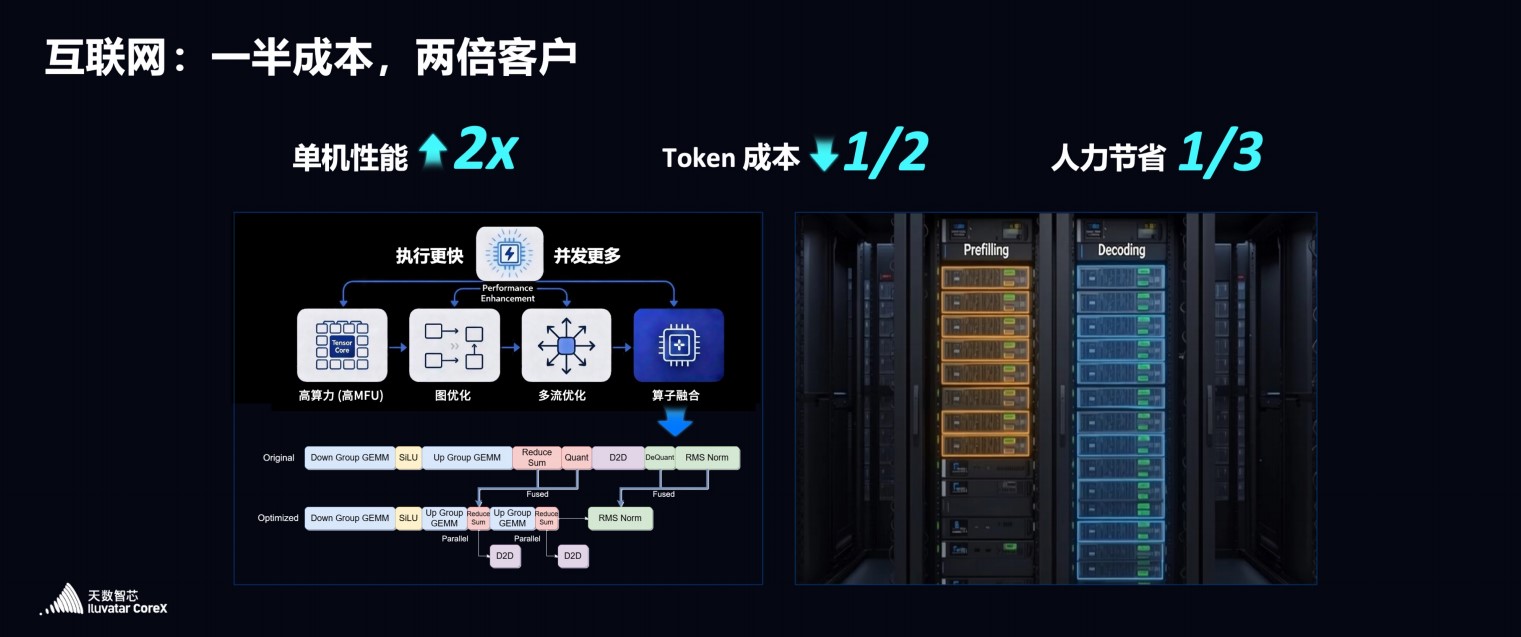
在互联网AI领域,单机性能比国际方案提升2倍,每Token成本下降一半,人力节省三分之一;在大模型适配上,达成95%算子复用;在科学探索领域,千卡集群稳定运行1000多天,已落地国内多家顶级学府;在金融领域,研报生成效率提升70%,量化分析响应速度提升30%;医疗领域,结构化病历生成时间缩至30秒/份,肠胃镜病灶定位精度提升30%。
结合此前的招股书看,天数智芯是行业少数全面披露客户数量、量产发货量、毛利等核心经营数据的厂商,信息的颗粒度和透明度体现出足够的“底气”。而在本次合作伙伴大会上,天数智芯不仅集中释放技术、产品等多重亮点,更以实打实的成果,展现出自身在国产GPU赛道上的硬核竞争力。
客户是“啃”出来的
GPU所处的大芯片赛道,技术门槛高,生态复杂多样决定了是一场长跑。无论是场景深耕还是生态建设,从来都不是一蹴而就。这一过程非常艰难,远非外界看到的“国产替代一片向好”,而是需要靠企业一个个客户“啃下来”。
天数智芯副总裁郭为还清楚记得早期拓展客户时遇到的尴尬。由于天数智芯的大量客户是商业客户(TO C属性),这类客户纯粹基于性价比、技术能力、生态兼容性做选择,无政策强制要求,对国产产品的初始信任度较低,且部分客户曾使用过其他友商产品,体验不佳,因此对国产GPU持谨慎态度。
“但过去几年通过我们的努力,逐渐将客户的这些疑虑打破。其核心在于在技术、产品、服务和生态等方面,直击客户和细分场景核心痛点,不玩虚的,聚焦实际价值。”郭为说。
这折射出国产GPU产品发展的关键路径,即在产品设计、服务等方面,以好用、可落地为方向。
天数智芯的定位是解决方案提供商,而非单纯半导体企业,这使得其能够通过软硬一体优化,解决“最后一公里”落地难题,更好地帮助客户解决实际问题,创造差异化价值,构建竞争壁垒。同时,公司技术与市场团队直接对接客户,快速捕捉真实需求,确保产品研发不脱离实际,在行业领域,组建专有团队,深度参与解决方案在场景的落地积累经验。这一点与NVIDIA的定位和模式非常接近。
而基于通用GPU生态,客户在国际品牌上的模型、算法可无缝迁移至天数的平台,无需改变现有使用习惯。在兼容性与迁移性上,长期积累的能耗优化、稳定运行能力也优于同类竞品。此外,天数智芯通过提供本地化深度调优支持,只要客户愿意尝试,架构团队可根据客户需求提供定制化调优,快速完成适配,同时提供极具竞争力的产品价格以及灵活的议价方式。
就这样,凭借技术实力,快速响应和定制化服务,天数智芯突破客户的信任壁垒。近年来随着落地案例增多,市场认可度也逐渐提升,拓展客户的效率已明显改善。除了在商业、工业等场景外,其解决方案在基因检测、海底勘探、地质勘探等尖端科研领域也已落地,生态丰富度在国内同类企业中较为突出。
值得一提的是,在客户服务和生态建设的过程中的实战经验,也反哺了天数智芯的产品设计与研发,从而让解决方案更适配实际场景。
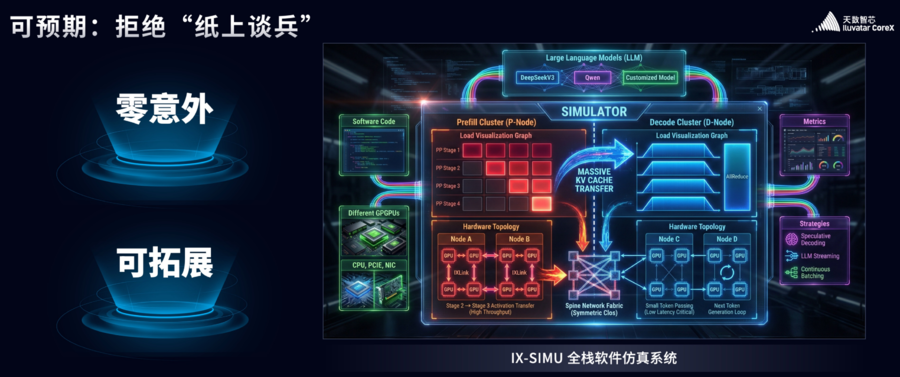
比如客户提出“跨场景适配性”需求,促使天数智芯强化生态兼容性;针对“稳定性担忧”,优化了容错机制与售后服务。客户在大规模算力集群投资前,担心性能不达标、落地效果不可控,仿真系统可提前模拟集群运行效果,精准预判性能与成本,解决客户“决策焦虑”。这一系统的研发,正是天数技术团队与客户深度沟通后的成果,体现了“需求驱动创新”。
“真正的伙伴会直面我们的不足,帮助产品优化。客户愿意花时间提问题,本质是认可产品、希望持续使用,这种反馈我们格外珍惜。”郭为告诉集微网。
此次会议上,天数智芯与硬件厂商、解决方案提供商等多家生态伙伴签署战略合作协议,进一步完善国产AI算力生态闭环。
什么是好用的GPU?如何衡量GPU价值?用户核心诉求是什么?天数智芯给出的答案是——落地是唯一真理,最终需回归应用性价比——这不仅包括产品采购阶段的性能性价比,更涵盖用户开发过程中的人力投入性价比。这一目标的实现,既依赖软件开发生态,也离不开合作伙伴的共建。如果说芯片和算力是应用落地的种子,那么系统和生态决定种子的生长上限。
国产GPU的底色
在不远的未来,当政策补贴与资本热度退潮,市场供需格局重塑后,国产GPU行业将彻底告别“野蛮生长”,迈入 “实力比拼” 阶段。“优胜劣汰” 的市场法则不可避免,唯有坚守技术自研底色、聚焦场景落地本质、深耕生态建设长远的企业,才能穿越周期、站稳脚跟。
国产GPU的真正价值,从来不是单纯的“替代”,而是摆脱对海外芯片的技术与供应链依赖,构建起 “自主可控、好用易用、成本适配”的本土算力体系。算力自主从来不是 “弯道超车” 的噱头,而是一场考验耐力与定力的 “马拉松”。天数智芯多年来 “不浮夸炫技、埋头攻落地” 的务实路径,或许正是这场算力革命中最需要的 “清醒剂”。
技术价值上,全栈自研架构是其核心“抗风险基石”—— 从计算单元IP到编译器、驱动100%自主可控。GPU研发创新没有捷径,天数选择了自研这条“最难的路”看似 “慢”,却避开了 “核心技术卡脖子” 的隐患,为自身产品迭代筑牢根基。
产业价值上,用“5.2万片交付量+300家量产客户”的硬数据证明,国产GPU绝非依赖政策红利的“伪需求产品”,而是能真正帮企业降低算力成本、提升业务效率的实用工具,跑通了“技术-产品-商业落地”的正向循环,为国产GPU树立更多信心,助力AI时代国产芯赋能千行百业。
行业价值上,其以“落地为王”的实践打破了行业的浮夸风气,这种务实哲学,不仅为自身积累了场景适配经验与客户黏性,塑造差异化的竞争力,同时也引领行业从“参数堆砌”到“需求导向”的转换。
天数智芯的实践印证了衡量GPU的价值唯一真理是应用落地,是最终应用性价比,是产品采购的性能、性价比以及用户开发使用的投入性价比。真正的国产替代价值,不在于短期市值高低、口号响亮,而在于能否稳定交付、解决行业实际痛点、构建可持续的盈利模式——这正是其增长逻辑的核心,也是其长期投资价值的底层支撑。
英伟达用三十年构建起CUDA生态护城河,国产GPU的崛起同样需要时间与耐心。真正的技术突围不在于营销声量,而在于能否在真实场景中创造不可替代的价值。当行业从“参数军备竞赛”转向“落地实效比拼”,那些沉下心打磨产品、深耕场景的企业,终将赢得市场尊重。
天数智芯的这堂“落地课”,或许正是国产GPU走向成熟的开始。
