

Meta 针对 OpenAI 的挖人竟然还在继续!
这或许是目前为止,扎克伯格挖走的最强技术人才。
就在刚刚,外媒 Wired 的一位资深 AI 领域记者爆料称,「多个消息源证实,OpenAI 知名研究员 Jason Wei 和另一位研究科学家 Hyung Won Chung 将双双离职,投奔 Meta。」
并且,他们二人的 Slack 账号已经被停用。机器之心也从 OpenAI 相关人士证实了该消息,「(Jason Wei)Slack 没了」,但是否是加入 Meta 还有待进一步证实。

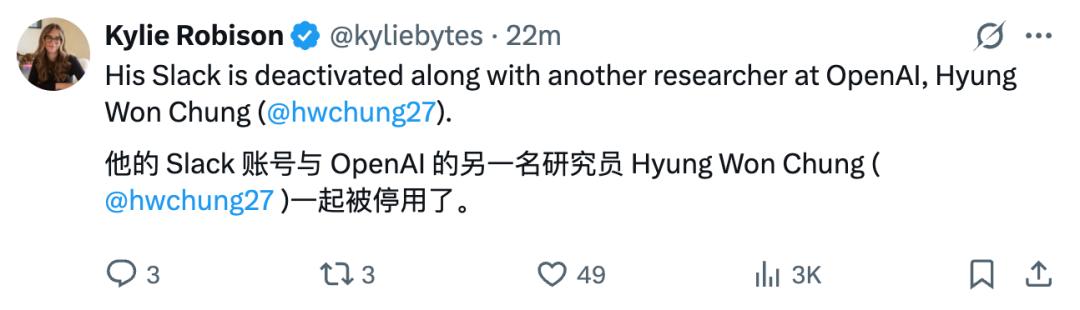
Jason Wei 是 OpenAI 的知名科学家,目前 AI 大模型领域里重要技术思维链(CoT)的主要作者,Hyung Won Chung 也是 o1 的核心贡献者之一。

Jason Wei 是 CoT 论文的第一作者,该论文的引用量已超过 1.7 万
如果你对他们的印象还不够深,还记得去年 12 月 OpenAI 连续两周的新产品发布会吗?坐在奥特曼旁边的就是 Hyung Won Chung,最右边的是 Jason Wei。他俩都毕业于 MIT,曾在谷歌工作,现在可能一起去了 Meta。

爆料消息出来不久,Jason Wei 并没有正面回应,而是发了一篇推特,介绍其长博客,探讨了验证非对称性以及「验证者」法则。
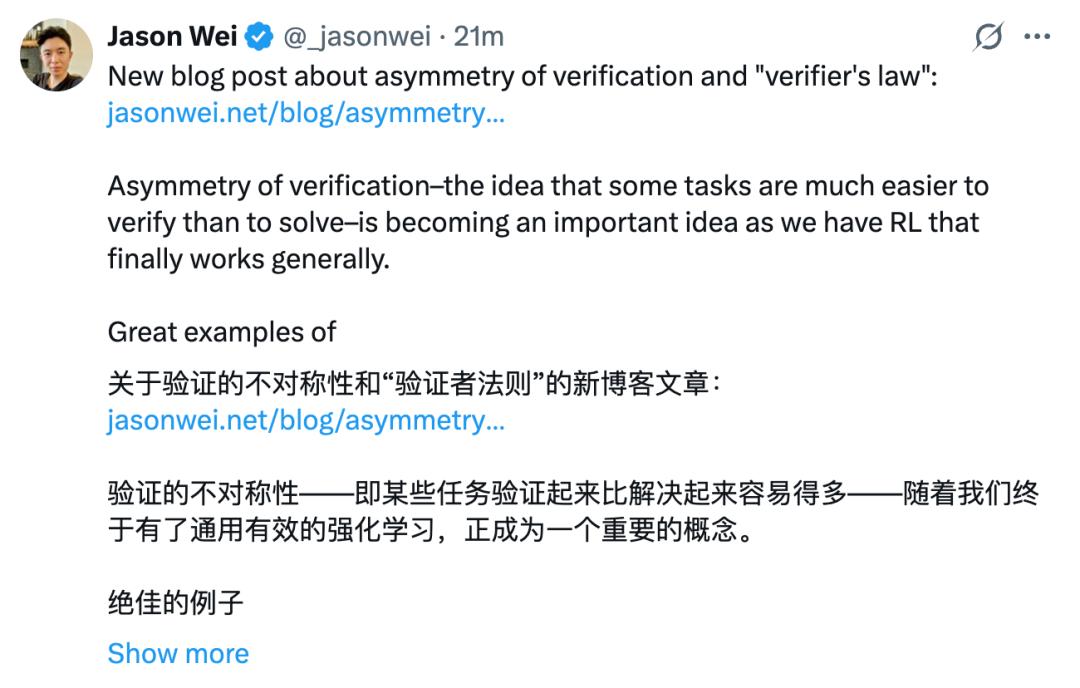
但评论区看热闹的大家伙似乎已经不关注他写了什么,都在恭喜他跳槽到 Meta。
在发了这篇技术博客没多长时间,Jason Wei 又发了一篇推特。

以下是原推内容翻译:
过去一年成为一名强化学习(RL)狂热爱好者,并且清醒时大部分时间都在思考 RL,这无意中教会了我一个关于如何过好自己生活的重要道理。
RL 中的一个核心概念是,你总是希望处于「同策略(on-policy)」状态:与其模仿别人成功的轨迹,不如采取自己的行动,并从环境给予的奖励中学习。显然,模仿学习(imitation learning)在最初引导模型达到非零通过率时很有用,但一旦模型能走出合理的轨迹,我们通常就会避免模仿学习,因为要充分发挥模型自身(与人类不同)优势的最佳方式是只从它自己的轨迹中学习。一个被广泛接受的实例是:在训练语言模型解决数学应用题方面,强化学习比简单地用人类编写的思维链进行监督微调效果更好。
人生也是如此。我们最初通过模仿学习(学校教育)来引导自己,这非常合理。但即使在我毕业后,仍有一个习惯:研究别人如何取得成功并试图模仿他们。有时会奏效,但最终我意识到,我永远无法完全超越他人,因为他们是在发挥他们的优势,而这些优势我可能并不具备。这可能是某位研究人员比我更成功地进行大胆尝试(运行 yolo),因为他们亲自搭建了代码库而我没有;或者一个非 AI 的例子:一位足球运动员利用我不具备的力量优势保持控球权。
进行同策略 RL 带来的启示是:要超越前辈(beat the teacher),必须走自己的路,承担风险并从环境中获取回报。例如,比起一般的研究人员,我更喜欢做两件事:(1) 大量审阅数据,(2) 进行消融研究以理解系统中各个组件的作用。有一次在收集数据集时,我花了几天时间审阅数据并给每位人类标注员提供个性化反馈,之后数据质量变得极佳,并且我对要解决的任务获得了宝贵的见解。今年早些时候,我花了一个月时间回溯并逐一消融研究之前在做深度研究时尝试做的每个决策。这花费了相当多的时间,但通过这些实验,我学到了关于哪种类型的 RL 效果好的独特经验。发挥自己的热情让我更有满足感,而且我现在感觉自己正走在为自己和自己的研究开辟一片更强大天地的道路上。
简而言之,模仿是好的,你必须在初始阶段这样做。但一旦你完成了足够的引导,若想超越前辈,就必须进行「同策略」的强化学习,学会扬长避短。
接下来,我们来看这两位研究员的履历。
Jason Wei
Jason Wei 是思维链(Chain of Thought,CoT)概念开山之作 ——「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」的第一作者,本科毕业就加入了谷歌。在那里,他推广了思维链提示概念,共同领导了指令调优的早期工作,并和 Yi Tay、Jeff Dean 等人合著了关于大模型涌现能力的论文。
2023 年 2 月,Jason Wei 加入 OpenAI,工作内容包括了推理模型 o1 和深度研究模型。

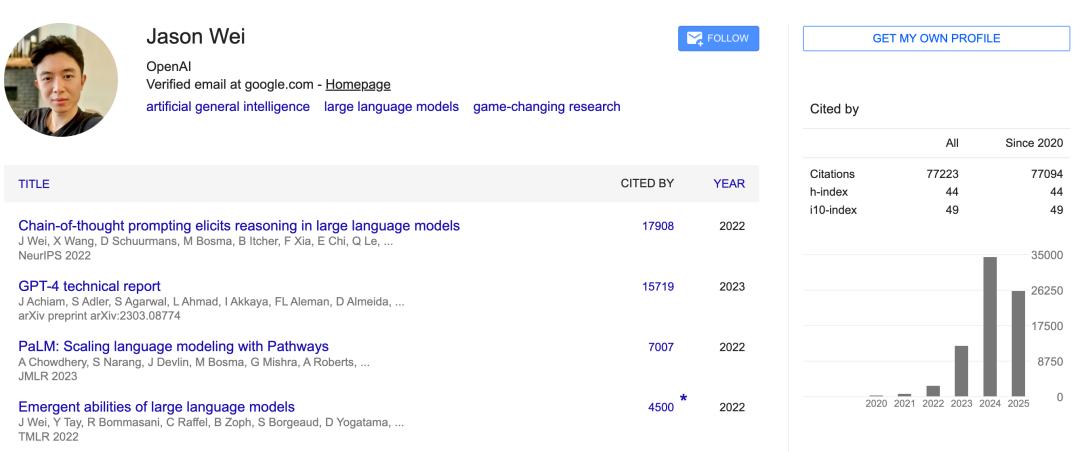
在 Google Scholar 主页上,Jason Wei 的论文引用量已经超过了 77k,其中前两位分别是 CoT 提示论文和 GPT-4 技术报告。
Hyung Won Chung
Hyung Won Chung 出生于韩国,OpenAI 研究科学家,专注于 LLM 的研究与应用。
他博士毕业于麻省理工学院,之后曾在谷歌从事了三年多的研究工作,期间参与了 PaLM(具有 5400 亿参数的大语言模型)、 BLOOM( 1760 亿参数的开放式多语言模型)、Flan-T5 等多个重要项目的研发。
离开谷歌后,Hyung Won Chung 于 2023 年加入 OpenAI。

在 OpenAI 工作期间,Hyung Won Chung 参与了多个重大项目的研究, 特别在以下项目中扮演了关键角色:o1-preview(2024 年 9 月),o1 正式版(2024 年 12 月)、Deep Research(2025 年 2 月),以及领导了 Codex mini 模型训练。
在 OpenAI 一些重大发布会上,我们也经常看到 Hyung Won Chung 的身影。
Hyung Won Chung 参与过的 OpenAI 一些发布会
作为 o1 系统的奠基贡献者,他在开发大语言模型的推理、搜索信息能力、以及使用强化学习策略方面发挥了重要作用。
Hyung Won Chung 还在多个重要场合分享洞见,包括斯坦福 CS25 讲座广受大家好评。
Hyung Won Chung 在 OpenAI 的研究工作中,他的贡献不仅推动了 o1 系列模型成为具有思考能力的前沿工具,也在编码智能体、系统评估和安全保障方面开辟了新路径,形成了一个从理论到应用、从开发到普及的完整研究生态。
随着 Jason Wei、Hyung Won Chung 两位大佬级别的人员离开,OpenAI 真的要被挖麻了。
