

清华开源 TurboDiffusion:AI 视频生成最高提速 200 倍,单张 RTX 5090 秒出大片
2025-12-25
/ 阅读约2分钟
来源:IT之家
清华TSAIL实验室与生数科技推出开源视频生成加速框架TurboDiffusion,推理速度提升100至200倍,采用SageAttention等技术,已提供多种规格模型权重下载,并针对不同硬件优化。
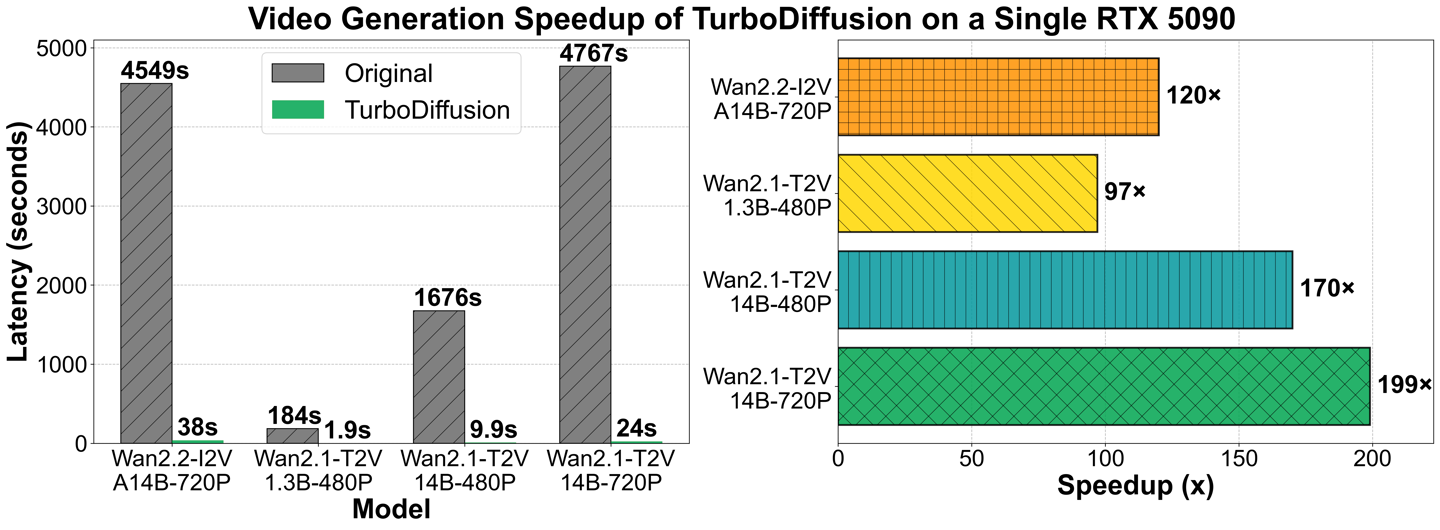
IT之家 12 月 25 日消息,清华大学 TSAIL 实验室联合生数科技推出开源视频生成加速框架 TurboDiffusion,该框架能在保持视频质量的前提下,将端到端扩散生成的推理速度提升 100 至 200 倍。
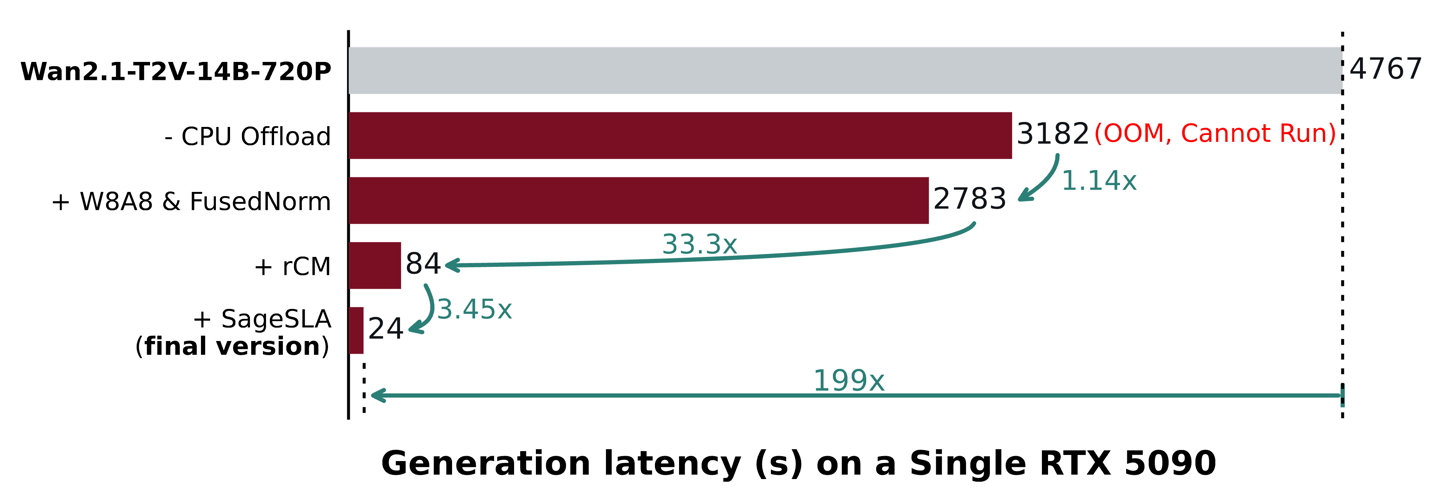
在技术方面,TurboDiffusion 为实现极致的推理速度,采用了 SageAttention 和 SLA(稀疏线性注意力机制)来加速注意力计算,显著降低了模型处理高分辨率视频时的算力开销。
其次,团队引入了 rCM(时间步蒸馏)技术,有效减少了扩散模型的采样步数。这些技术方案的深度融合,让模型在保持生成效果一致性的基础上,大幅削减了计算延迟。
GitHub 页面公布的实测数据展示了惊人的性能跃升。在单张 RTX 5090 显卡上测试 Wan-2.1-T2V-1.3B-480P 模型,生成 5 秒视频的原版耗时为 184 秒,而 TurboDiffusion 仅需 1.9 秒。

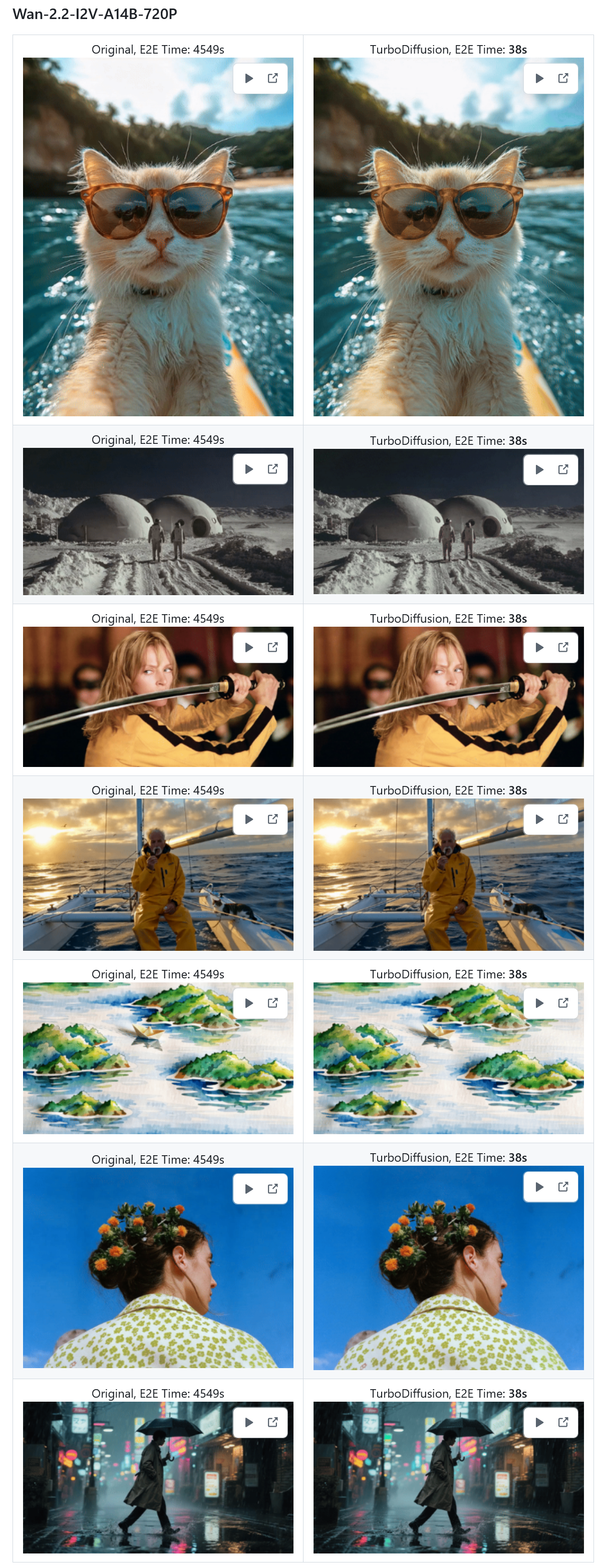
对于参数量更大的 Wan-2.2-I2V-A14B-720P 模型,原版生成耗时高达 4549 秒(约 1.2 小时),TurboDiffusion 将其压缩至 38 秒。IT之家附上相关截图如下:

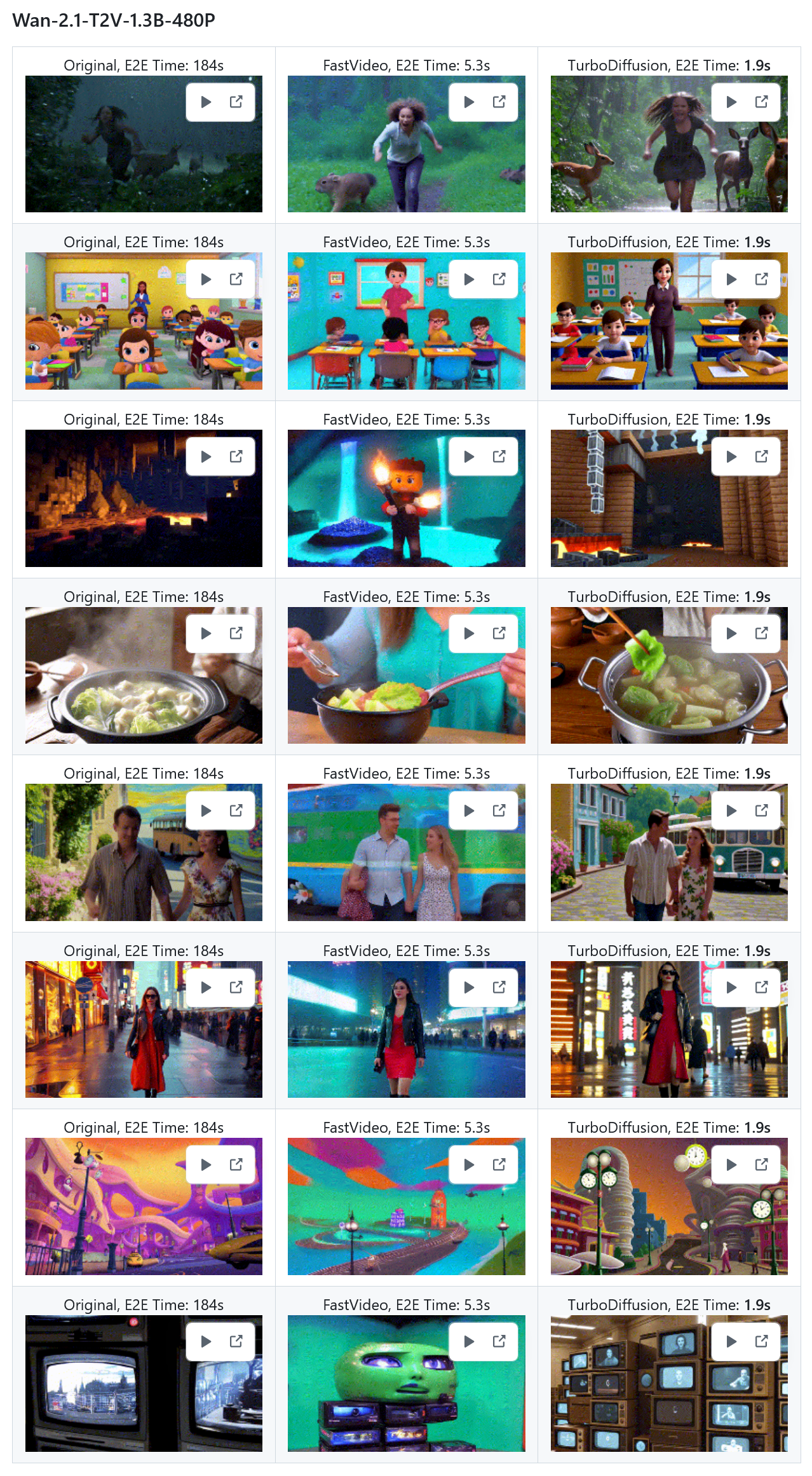
即便是在 Wan-2.1-14B-480P 模型上,耗时也从 1676 秒骤降至 9.9 秒,速度远超目前市面上的 FastVideo 等加速方案。

TurboDiffusion 目前已提供多种规格的模型权重下载,并针对不同硬件进行了针对性优化。针对 RTX 5090、RTX 4090 等显存有限的消费级显卡,团队提供了量化版(Quantized)权重,并建议开启线性层量化功能;而对于拥有 80GB 以上显存的 H100 等工业级显卡,则推荐使用非量化版本以获得最佳效果。
